



Power BI Desktop is een prachtige tool om snel data-analyses te kunnen uitvoeren. Je connecteert op een databron, importeert en combineert wat datasets, definieert daarbovenop je favoriete calculaties en visualiseert de informatie. Je bent een echte data virtuoso.
Maar zo gaat het soms in het leven, het kan eens fout lopen. Je stuit op een dataset met whoa veel records. Je Power BI file doet zijn best om de ganse hap te verwerken maar het plezier is er duidelijk van af. Pas na een paar eindeloze minuten kan je aan terug de slag.
Gelukkig zijn er een paar eenvoudige tricks die je kunt toepassen waardoor jouw Power BI ervaring terug top wordt:
De test wordt uitgevoerd op een medium range laptop. Verder maak ik gebruik van de ContosoRetailDW database, vrij verkrijgbaar bij Microsoft online [1].
Om de testresultaten wat duidelijker naar voren te brengen werd de dbo.FactOnlineSales tabel uitgebreid van 12 miljoen naar iets meer dan 100 miljoen records.
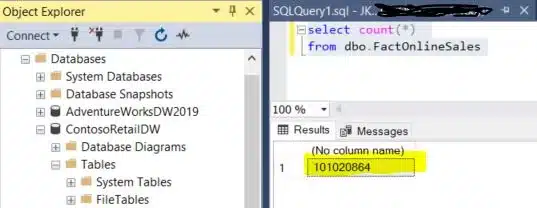
In onze Power BI file wordt een eenvoudig model gedefinieerd. Naar good practice importeren we volgende tabellen: FactOnlineSales, DimProduct, DimStore en DimDate.
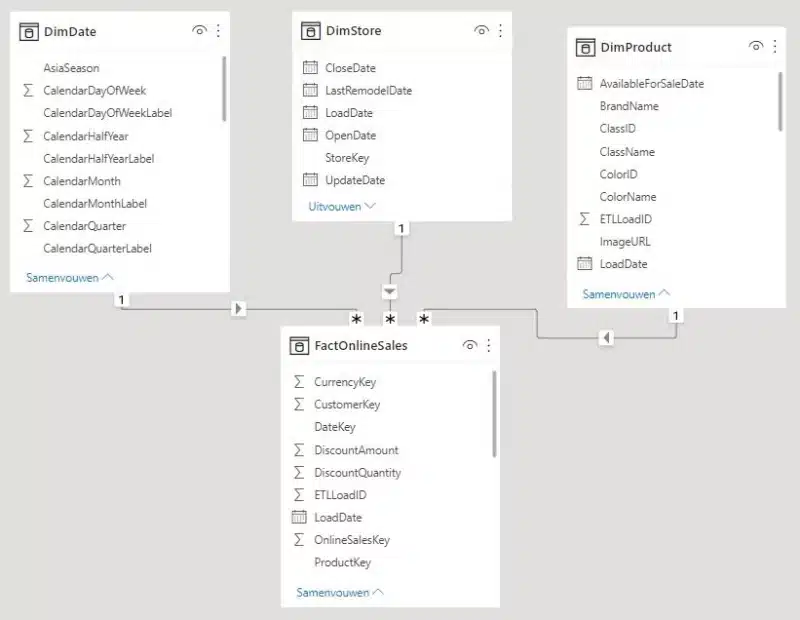
De import-opslagmode laadt elke tabel op in memory en zorgt daarbij dat de gegevens in memory heel straf gecomprimeerd worden. Grafieken, matrices en andere Power BI visuals wordt daardoor razendsnel van data voorzien.
Maar komt dat wel goed in ons geval?
Het importeren van de datasets loopt goed, loopt nog steeds, en blijft lopen. Pas na 6 minuten kan ik aan de slag om relaties en calculaties in het model te definiëren. Een tabel met 100 miljoen rijen is niet niks: ook de opslag van de PowerBi file duurt tientallen seconden en resulteert in een file van anderhalve GB.
Verder kan ik bij elke nieuwe refresh van de file terug minutenlang wachten op de up-to-date gebrachte informatie. Nee, dat is niet werkbaar.
In deze post doe ik een rework van de PowerBI file die niet alleen 3000 keer kleiner zal worden, maar bovendien 100 keer sneller kan werken.

Een oplossing kan zijn om de data niet te importeren maar te halen uit een SSAS Tabular cube waarin de refresh van het datamodel gepland kan worden buiten de kantooruren. Maar wat als je geen dergelijke oplossing kan gebruiken?
Trick 1 is het omvormen van de grote tabel, hier de FactOnlineSales met +100 miljoen rows, naar een tabel met DirectQuery opslag mode.
Wanneer een tabel in DirectQuery wordt opgeladen, onthoudt de Power BI file alleen de metadata. De records zelf blijven in de oorspronkelijk source staan en worden niet in memory opgeladen.
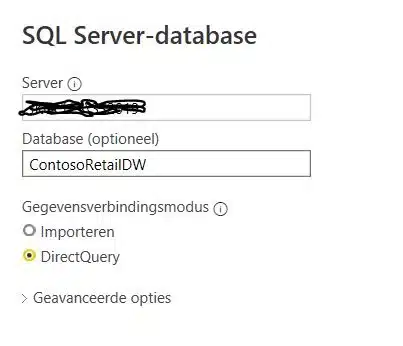
Met DirectQuery tabellen, gaat de DAX-engine bij het renderen van Power BI visuals met Power Query de source gaan bevragen. In dit voorbeeld is de source mijn ContosoRetailDW SQL Server database. In het geval van SQL Server wordt een SQL-query uitgevoerd door de database engine.
Er is op dit ogenblik geen ‘simpele’ manier om een imported model om te vormen naar een model met DirectQuery opslag mode. We maken een nieuwe file hiervoor en laden dezelfde tabellen op, ditmaal dus in DirectQuery opslagmode.

Het laden gaat supersnel! Verder zien we dat de tabellen in het modelschema van een blauwe rand voorzien worden. Van elke tabel kan je in de Geavanceerde Eigenschappen zien wat de opslagmodus is.
Zolang we geen visuals in ons rapport hebben, gaat het werken met de file heel vlot: er worden immers geen records in memory opgeladen.
De interactie met visuals verloopt verassend minder snel. Een simpele grafiek die een sum(FactOnlineSales[SalesAmount]) toont per CalendarYear heeft algauw enkele seconden nodig. Hoeveel seconden er precies nodig zijn, kan je achterhalen met behulp van de ingebouwde Performance Analyzer tool.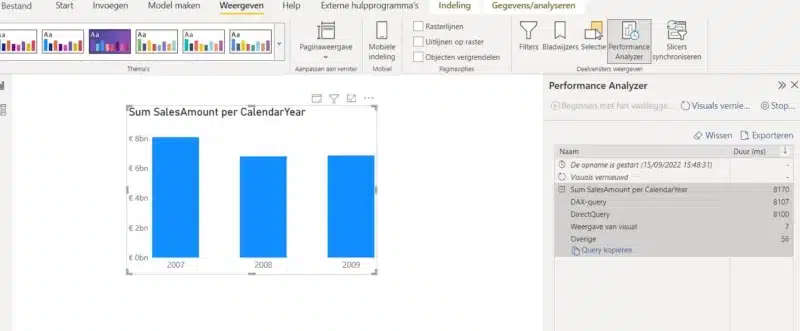
De gegevens van meer dan 100 miljoen records staan niet meer klaar in memory. Ze worden nu uit de database tabel ingelezen.
Voor mijn Sum SalesAmount per CalendarYear chart zie je hoe de DAX Query engine vooral tijd spendeert aan het uitvoeren van de DirectQuery, namelijk 8107 milliseconden. Dat raak je aan de straatstenen niet kwijt!
Ideaal ware dat we zowel het model snel kunnen opladen en refreshen, alsook een vlotte user experience kunnen bezorgen wat de visuals betreft.
Om dat te realizeren open we terug onze toolbox. We gaan gebruik maken van “user-defined aggregations”.
Aggregaties kunnen de bevraging van heel grote DirectQuery datasets versnellen. Daarbij wordt geaggregeerde data gecached in memory. Naargelang de soort data bron, kan een aggregatietabel gecreëerd worden in de bron als een tabel of view, als een query, of als een geïmporteerde tabel met behulp van Power Query.
In ons voorbeeld maken we gebruik van een view die de SalesAmount en de SalesQuantity cijfers aggregeert op datum:
CREATE VIEW [dbo].[vw_aggregate_FactOnlineSales_Date] AS
SELECT FOS.DateKey, sum(SalesAmount) SalesAmount, sum(SalesQuantity) SalesQuantity
FROM [ContosoRetailDW].[dbo].[FactOnlineSales] FOS
GROUP BY FOS.DateKey
select count(*) from dbo.vw_aggregate_FactOnlineSales_Date
1096 rows
Deze geaggregeerde dataset telt 1096 records en dat is peanuts vergeleken met onze 100 miljoen rijen uit de fact tabel.
We importeren deze tabel in ons model, dus ja, met import opslagmodus.
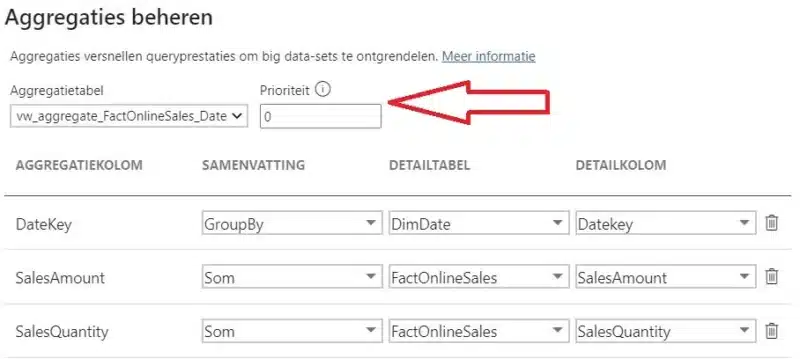
We definiëren de vw_aggregate_FactOnlineSales_Date dataset als een aggregatietabel: click Meer Opties en kies Aggregaties beheren.
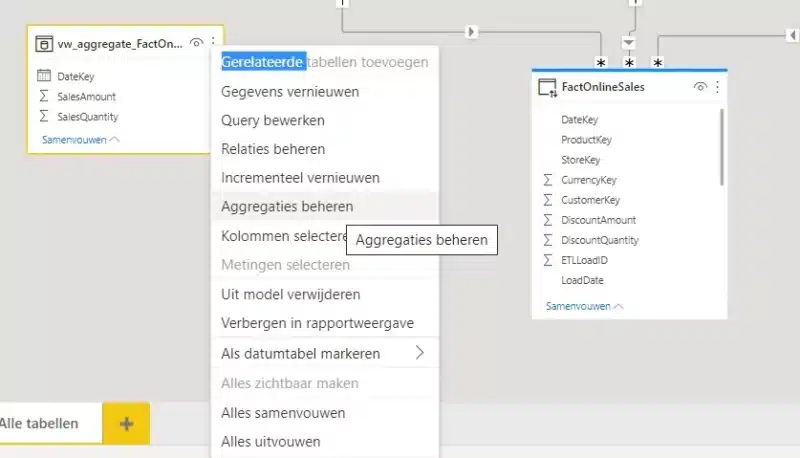
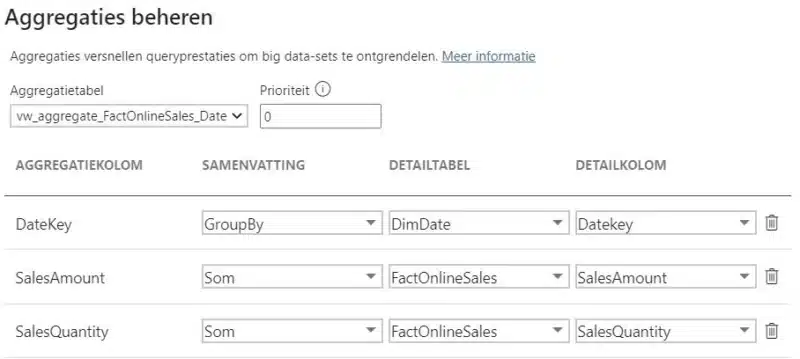
In deze dialoog vertellen we aan PowerBI dat de in memory opgeladen dataset (import) kan gebruikt worden wanneer er een query SalesAmount e/o SalesQuantity cijfers opvraagt al dan niet in combinatie met de key van de DimDate tabel.
Merk op dat zodra een tabel als een aggregatie wordt gedefinieerd deze niet meer zichtbaar is voor de eindgebruiker.
We definiëren ook een 1-to-many relatie met de DimDate tabel. Deze laatste staat in DirectQuery mode. De aggregatie tabel staat in importmode. De relatie tussen beide kan niet ogenblikkelijk afgechecked worden, vandaar de “open haakjes” in de relatieaanduiding.
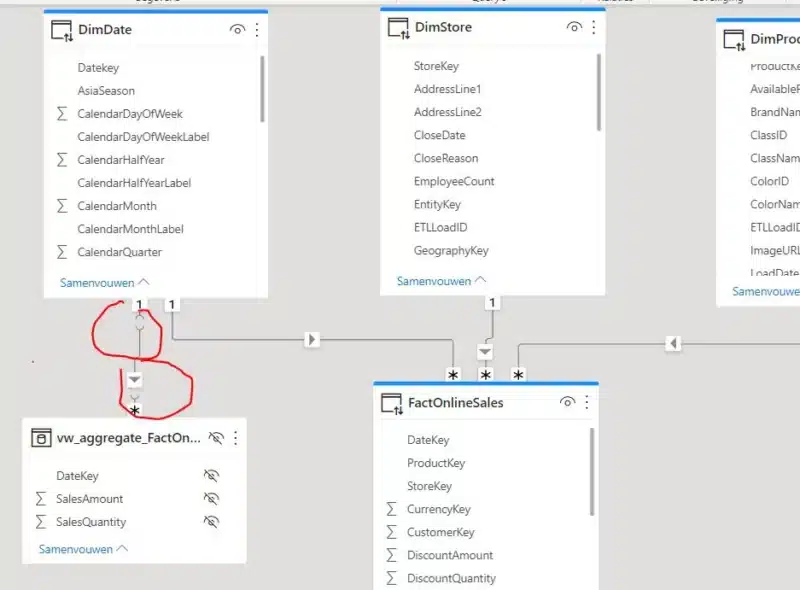
De imported aggregatietabel fungeert nu als een “shadow copy” in memory van onze reuze FactOnlineSales. Bij het querying van de measures, SalesAmount e/o SalesQuantity, wordt het resultaat vanuit de DAX-engine razendsnel berekend. In plaats van de 100 miljoen rijen in de database tabel te doorploegen, wordt nu handig gebruik gemaakt van de 1096 records die al geäggregeerd zijn op de DateKey.
In de rapportweergave vernieuwen we het model voor de actuele versie, en we doen de test.
Blijkbaar doet ons PowerBI model dit alleen zolang we enkel een van de measures gebruiken, al dan niet in combinatie met de DateKey. In de gevallen waar we andere attributen gaan gebruiken, wordt terug een DirectQuery uitgevoerd.
Een table visual met alle DateKeys rendert quasi ogenblikkelijk.
Refreshen we onze grafiek die CalendarYear gebruikt, dan duurt dit terug een kleine 10 seconden. Hoe komt dat nu? Dat is niet wat we willen.
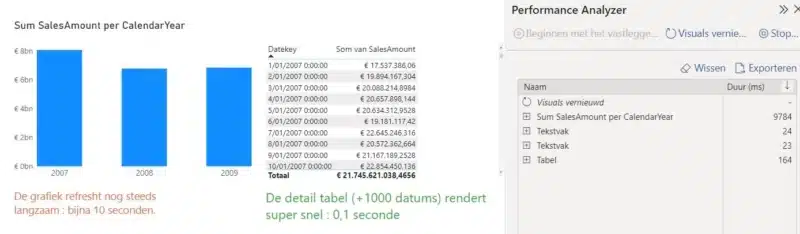
Ondanks het feit dat we ook een relatie hebben tussen DimDate en de aggregatietabel, blijft de performance van onze grafiek ondermaats. Omdat DimDate in DirectQuery opslagmodus staat kan de DAX-engine alleen van de aggregatie in memory gebruiken maken wanneer we de Datekey gebruiken. Om bv op CalendarYear te aggregeren moet er terug opnieuw naar de onderliggende database een SQL-query gestuurd worden die DimDate joined met de 100 miljoen rijen van de Fact tabel.
We lossen dit op door van DimDate een Dual opslagmodus tabel te maken (tabel eigenschappen Geavanceerd).
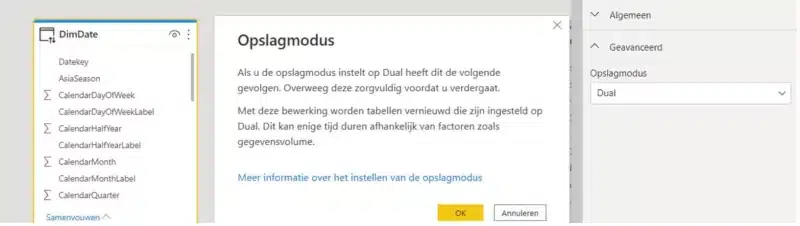
Daarbij krijg je een warning dat alle data van die tabel terug in memory geladen wordt. Click OK.
Van de DimDate wordt nu ook een copy in memory bijgehouden. Daardoor kunnen queries naar de geaggregeerde measures in combinatie met DimDate attributen rechtstreeks vanuit memory berekend en aangeleverd worden.
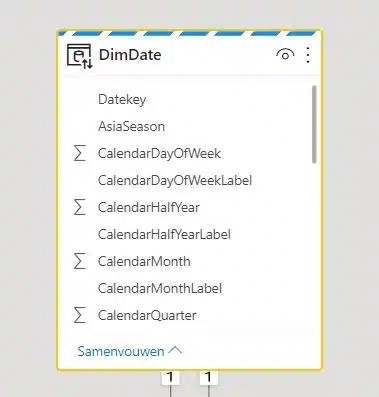
Merk op dat de hoofding van een Dual opslagmode tabel een stippellijn is geworden.
Het refreshen van de chart alsook van de detail tabel gebeuren allebei nu razendsnel. Er wordt geen DirectQuery meer doorgestuurd naar de onderliggende database.
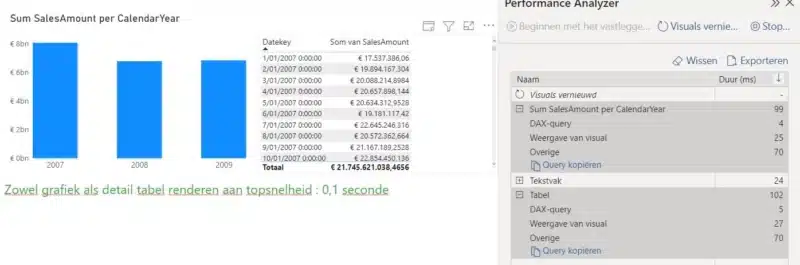
Zodra we de andere dimensies betrekken in onze Visuals krijgen we terug slechtere antwoordtijden omwille van DirectQueries die niet alle data uit memory kunnen halen.
De oplossing hier is om een “betere aggregatie” te definiëren op granulariteit van DimDate, DimStore en DimProduct.
Bv. Als volgt
CREATE VIEW [dbo].[vw_aggregate_FactOnlineSales_Date_Store_Product] AS
SELECT FOS.DateKey, FOS.ProductKey, FOS.StoreKey ,sum(SalesAmount) SalesAmount, sum(SalesQuantity) SalesQuantity
FROM [ContosoRetailDW].[dbo].[FactOnlineSales] FOS
GROUP BY FOS.DateKey, FOS.ProductKey, FOS.StoreKey
Deze nieuwe aggregatie wordt terug geimporteerd, als aggregatie aangemerkt (zie hierboven), gelinked met de dimensies (idem) en de dimensies zelf worden op Dual opslagmodus gezet (en idem).
In principe kan je per fact tabel verschillende aggregaties definiëren: bv. een aggregatie op DimDate, een aggregatie op DimDate én DimProduct, een aggregatie op DimDate én DimCustomer.
Wanneer er een vraag komt naar het aggregeren van cijfers op basis van datum, dan heeft PowerBI in ons voorbeeld drie mogelijkheden. De ene zal wat sneller zijn dan de andere naargelang het aantal records in de aggregatie.
In dergelijke gevallen weet de DAX-query engine echter niet welke aggregaties eerst uitgeprobeerd moeten worden. Die volgorde kan je aansturen met de Prioriteit eigenschap in de aggregatie definitie. De aggregatie met de hoogste prioriteit wordt eerst uitgeprobeerd.
Heb je een Power BI Premium licentie? Dan heb je geluk, daar bestaat de mogelijkheid om in Power BI service automatische aggregaties te laten aanmaken en dat op basis van de door het systeem gedetecteerde user queries voortkomende uit het gebruik van Power BI files. Meer info daarover hier https://powerbi.microsoft.com/en-in/blog/announcing-general-availability-of-automatic-aggregations.
Zo dat was spannend, niet?
Besluit! In geval van heel grote tabellen kan je een DirectQuery datamodel uitrusten met Aggregaties en Dual opslagmodus tabellen zodat je PowerBI visuals terug snel renderen.
[1] Microsoft Contoso BI Demo Dataset for Retail Industry, https://www.microsoft.com/en-us/download/details.aspx?id=18279
– Franky Leeuwerck, Kohera

Crafted by ![]()
Crafted by ![]()




