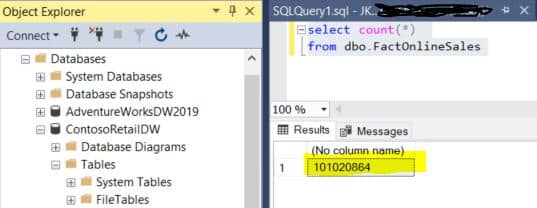
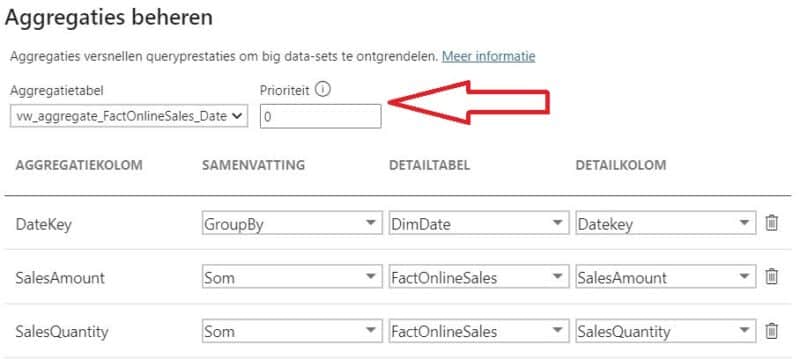
Ondanks het feit dat we ook een relatie hebben tussen DimDate en de aggregatietabel, blijft de performance van onze grafiek ondermaats. Omdat DimDate in DirectQuery opslagmodus staat kan de DAX-engine alleen van de aggregatie in memory gebruiken maken wanneer we de Datekey gebruiken. Om bv op CalendarYear te aggregeren moet er terug opnieuw naar de onderliggende database een SQL-query gestuurd worden die DimDate joined met de 100 miljoen rijen van de Fact tabel.
We lossen dit op door van DimDate een Dual opslagmodus tabel te maken (tabel eigenschappen Geavanceerd).

Daarbij krijg je een warning dat alle data van die tabel terug in memory geladen wordt. Click OK.
Van de DimDate wordt nu ook een copy in memory bijgehouden. Daardoor kunnen queries naar de geaggregeerde measures in combinatie met DimDate attributen rechtstreeks vanuit memory berekend en aangeleverd worden.
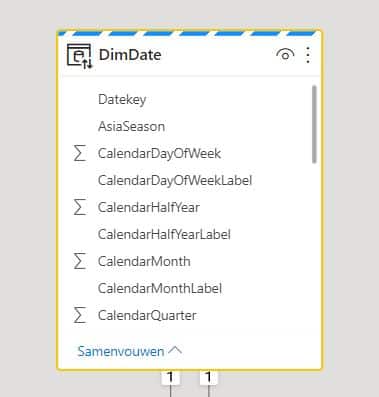
Merk op dat de hoofding van een Dual opslagmode tabel een stippellijn is geworden.
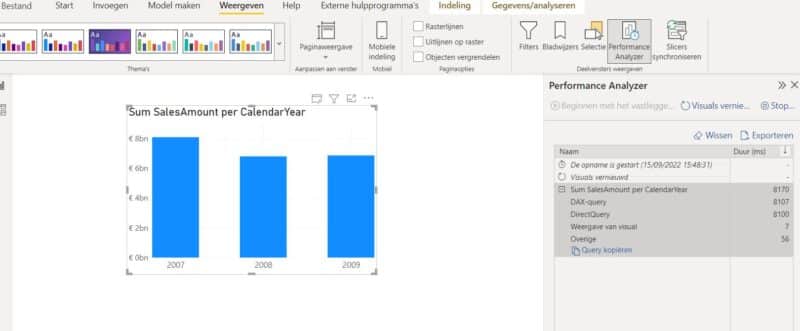
Het refreshen van de chart alsook van de detail tabel gebeuren allebei nu razendsnel. Er wordt geen DirectQuery meer doorgestuurd naar de onderliggende database.
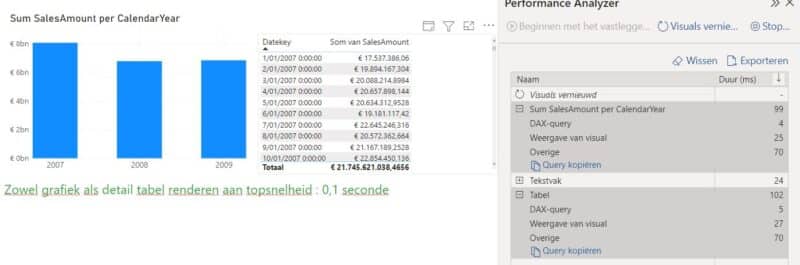
Zodra we de andere dimensies betrekken in onze Visuals krijgen we terug slechtere antwoordtijden omwille van DirectQueries die niet alle data uit memory kunnen halen.
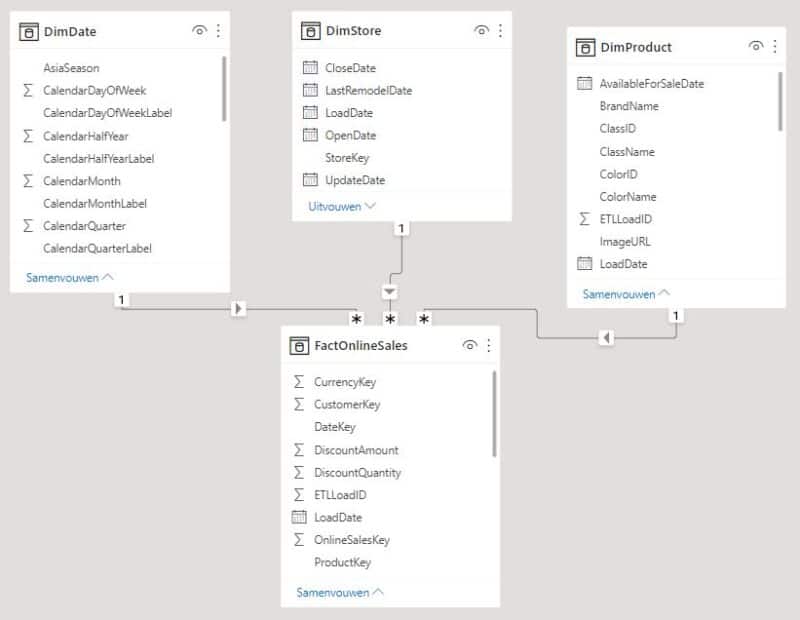
De oplossing hier is om een “betere aggregatie” te definiëren op granulariteit van DimDate, DimStore en DimProduct.
Bv. Als volgt
CREATE VIEW [dbo].[vw_aggregate_FactOnlineSales_Date_Store_Product] AS
SELECT FOS.DateKey, FOS.ProductKey, FOS.StoreKey ,sum(SalesAmount) SalesAmount, sum(SalesQuantity) SalesQuantity
FROM [ContosoRetailDW].[dbo].[FactOnlineSales] FOS
GROUP BY FOS.DateKey, FOS.ProductKey, FOS.StoreKey
Deze nieuwe aggregatie wordt terug geimporteerd, als aggregatie aangemerkt (zie hierboven), gelinked met de dimensies (idem) en de dimensies zelf worden op Dual opslagmodus gezet (en idem).