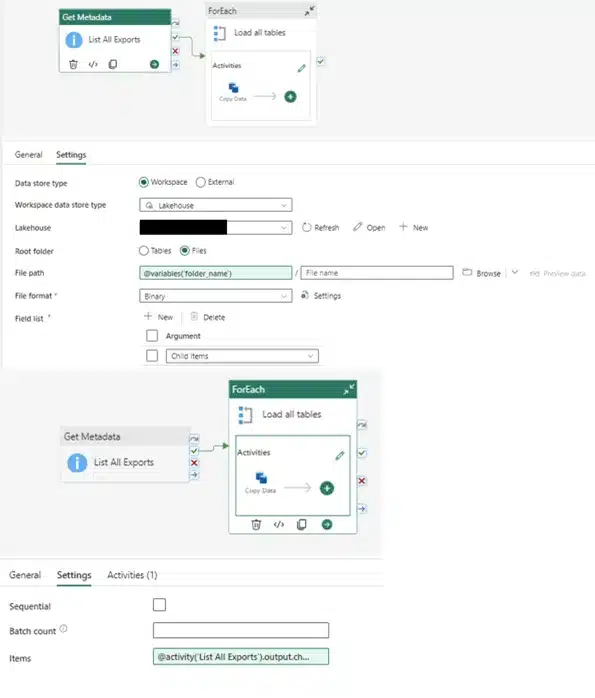
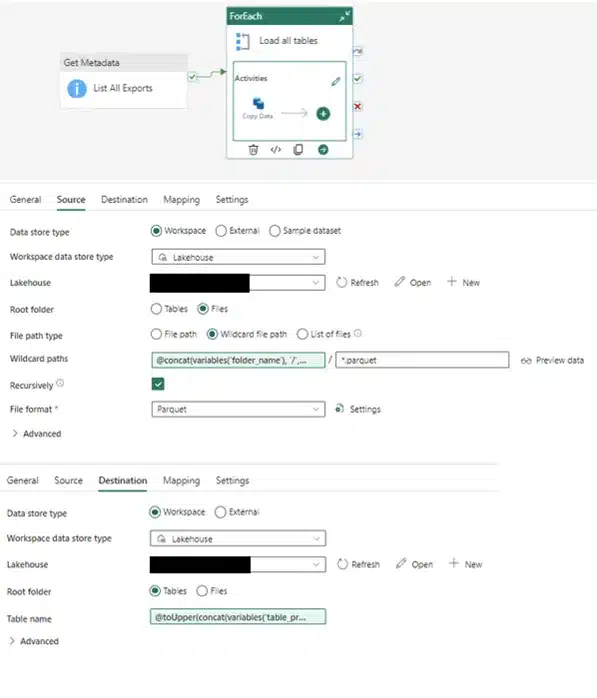
Establish the connection to OneLake
Step 1: First create a JSON file with the Service Principal credentials. I put this file in the config folder of my project
|
“tenant_id”: “<tenant_id>”,
“client_id”: “<client_id>”,
“client_secret”: “<client_secret>”
|
Step 2: Next, import the dependencies. Make sure they’re installed in the Python environment you’ll be using. From the Azure SDK we import the package to manage the datalake (OneLake) and we also import the package for authenticating with the Service Principal using a client secret. Lastly, the JSON package is imported to read our config file created in step 1.
| from azure.storage.filedatalake import DataLakeServiceClient
from azure.identity import ClientSecretCredential
import json |
Step 3: Make a Credential object for the Service Principal.
| config = json.load(open(“config/service_principal.json”))
credential = ClientSecretCredential(
tenant_id=config.get(‘tenant_id’),
client_id=config.get(‘client_id’),
client_secret=config.get(‘client_secret’)
) |
Step 4: Put the name of the workspace and the lakehouse in variables so it can be easily reused.
| workspace = ‘<Name of the fabric workspace>’
lakehouse = ‘<Name of the lakehouse in the fabric workspace>’
files_directory = ‘<Name of the folder under files in the fabric lakehouse>’ |
Step 5: Create a DataLakeServiceClient object. This is an object at the OneLake level. Next use this object to create a FileSystemClient object. The FileSystemClient is on the workspace level. Once we have this, the preparation is done. Now we can start doing stuff.
| service_client = DataLakeServiceClient(account_url=”https://onelake.dfs.fabric.microsoft.com/”, credential=credential)
file_system_client = service_client.get_file_system_client(file_system = workspace) |
Playtime!
Below are some examples of what we can do with our FileSystemClient object.
Example 1: List all the folders starting from a specific path in OneLake
| paths = file_system_client.get_paths(path=f'lakehouse.Lakehouse/Files/files_directory’)
for path in paths:
print(path.name) |
Example 2: Create a new (sub)folder on OneLake
| new_subdirectory_name = ‘test’
directory_client = file_system_client.create_directory(f'lakehouse.Lakehouse/Files/files_directory/new_subdirectory_name’) |
Example 3: Upload a file to OneLake
| vm_file_path = r’C:\test\onelake\vm_test.csv’
onelake_filename = ‘onelake_test.csv’
directory_client = file_system_client.get_directory_client(f'lakehouse.Lakehouse/Files/files_directory/test’)
file_client = directory_client.get_file_client(onelake_filename)
with open(file=vm_file_path, mode=”rb”) as data:
file_client.upload_data(data, overwrite=True) |
Example 4: Download a file from OneLake
| onelake_filename = ‘onelake_test.csv’
vm_file_path = r’C:\test\onelake\download_onelake_test.csv’
directory_client = file_system_client.get_directory_client(f'lakehouse.Lakehouse/Files/files_directory/test’)
file_client = directory_client.get_file_client(onelake_filename)
with open(file= vm_file_path, mode=”wb”) as local_file:
download = file_client.download_file()
local_file.write(download.readall()) |
Example 5: Append to a CSV file on OneLake
| onelake_filename = ‘onelake_test.csv’
text_to_be_appended_to_file = b’append this text!’
directory_client = file_system_client.get_directory_client(f'lakehouse.Lakehouse/Files/files_directory/test’)
file_client = directory_client.get_file_client(onelake_filename)
file_size = file_client.get_file_properties().size
file_client.append_data(text_to_be_appended_to_file, offset=file_size, length=len(text_to_be_appended_to_file))
file_client.flush_data(file_size + len(text_to_be_appended_to_file)) |
Example 6: Delete a file from OneLake
| onelake_filename = ‘onelake_test.csv’
directory_client = file_system_client.get_directory_client(f'lakehouse.Lakehouse/Files/files_directory/test’)
file_client = directory_client.get_file_client(onelake_filename)
file_client.delete_file() |
Example 7: Delete a directory from OneLake
| directory_client = file_system_client.get_directory_client(f'lakehouse.Lakehouse/Files/files_directory/test’)
directory_client.delete_directory() |