



Naar aanleiding van een migratieproject bij een van onze klanten, kreeg ik inspiratie om enkele zaken rond Partitioning uit te klaren. Partitioning is geen performance feature, maar is voornamelijk een methode om het management van grote tabellen te vergemakkelijken. Dat betekent dat het geen invloed kan hebben op de performance. Wel integendeel, het kan zowel positieve als negatieve impact hebben op de query’s.
Partitioning heeft een groot aantal voordelen:
Met partitioning, kunnen we een tabel opdelen in verschillende kleinere logische tabellen. We kunnen er dan terwijl ook voor zorgen dat elke logische tabel op z’n eigen storage komt te staan. Wat hebben we nodig om te partitioneren?
Dit is waarschijnlijk een van de belangrijkst keuzes die we moeten maken wanneer we onze tabel gaan partitioneren. Een partition key zou idealiter moeten deel uitmaken van de “where clause” in elke query. Een juiste keuze van de key bepaald of SQL Server “Partition elimination” gaat toepassen in z’n query plans of niet. Partition elimination kan voor een performance boost zorgen op uw query’s.
De partition key is gebaseerd op de waarden van 1 en slecht 1 kolom in je gepartitioneerde tabel. Indien men geen direct bruikbare kolom heeft in de tabel kan men de partition key ook baseren op een calculated kolom.
De partitie functie definieert hoe de data moeten worden gepartioneerd, gebaseerd op de gekozen partition key. Wanneer we bijvoorbeeld een datum als partition key kiezen, kunnen we via de partition function bepalen of er gepartitioneerd wordt op dag, week, maand, kwartaal of jaar. Dit doen we door grenswaarden aan te geven in de partition functie.In de partition functie gaan we ook aangeven of we linkse of rechtse partitiegrenzen willen.
Een tabel wordt in een bepaalde filegroup geplaatst tijdens zijn creatie. Indien we een gepartitioneerde tabel creëren, gaan we de tabel i.p.v. in een filegroup in een partitie schema plaatsen. Een partitie schema is in feite niets anders dan een verzameling van 1 of meerdere filegroepen gerelateerd aan hun bijhorende storage.
Dus we hebben nodig:
We nemen default storage van de Database voor dit voorbeeld, met de default primary filegroep. In de AdventureWorks database willen we tabel SalesOrderHeader gaan partitioneren op jaar. De tabel staat op dit ogenblik in FG Primary.
CREATE TABLE [Sales].[SalesOrderHeader](
[SalesOrderID] [int] IDENTITY(1,1)
[RevisionNumber] [tinyint] NOT NULL,
[OrderDate] [datetime] NOT NULL,
....
) ON [PRIMARY]
GO
Als partition key gaan we OrderDate gebruiken.
Onze Partition function wordt:
Create partition function pJaar (DateTime)
AS range Right for values ('20050101','20060101','20070101','20080101','20090101')
En voor Partition schema houden we het eenvoudig, alle partities in PRIMARY
In het partitie schema verwijzen we naar onze partitie functie
CREATE PARTITION SCHEME pSchema AS PARTITION PJaar ALL TO([PRIMARY]);
Eens dit gecreëerd is, kunnen we onze gepartioneerde tabel aanmaken. In dit geval nemen we een nieuwe tabel.
CREATE TABLE [Sales].[SalesOrderHeader_Partitioned](
[SalesOrderID] [int] IDENTITY(1,1),
[RevisionNumber] [tinyint] NOT NULL,
[OrderDate] [datetime] NOT NULL
) ON pSchema(OrderDate);
GO
We gebruiken de partition key als parameter voor het partition schema .
Als we de tabel gaan opvullen zullen we zien dat er 6 partities opgevulde worden (5 gedefinieerd + 1 voor ondergrens (alles kleiner dan 01012005)).
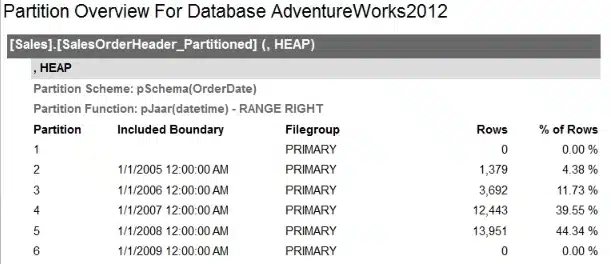
Om terug te komen op de partitie functie: linkse of rechtse partitie grenzen, that’s the question?
Een voorbeeld dringt zich op:
Dit is de Tabel met 1 integer column en volgende waarden:
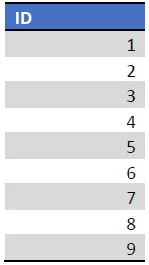
We kiezen voor ons voorbeeld een tabel, met als partition key de column [ID], een integer met waarden van 1 tem 9. De stijgende volgorde is louter toevallig.
Stel, we willen partitoneren op de waardes 4 & 8 dus maken we de volgende partition functies
Create Partition function PLeft (INT)
AS range Left for values (4,8)
Create Partition function PRight (INT)
AS range Right for values (4,8)
We laden nu bovenstaande data, in de gepartitoneerde tabellen Tbl_Left en Tbl_Right met partiton key [ID] en bekijken hoe data verdeeld worden.

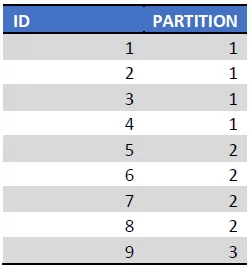
Bij Range Left zien we dat partition 1 alle waarde bevat <= (LE) 4 en partition 2 alle waarden > 4 en <= 8. Partition 3 bevat alles > 8

De actuele partitie grens behoort tot de linkse partitie
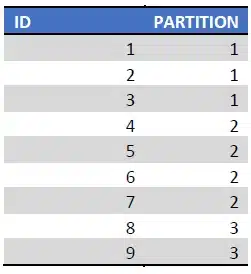
Bij Range Rigt bevat partition 1 alles < 4, partition 2 >= 4 en < 8 en partition 3 alles >= 8

De actuele partitie grens behoord tot de rechter partitie.
Visueel wordt dit voor Tbl_Left
En voor Tbl_Right
Je kan ook steeds testen in welke partition uw partition key waarde zal terecht komen door gebruik te maken van $PARTITION.
Vb:
SELECT $PARTITION.PRight (4) ; è returns valuee
SELECT $PARTITION.PLeft (4) ; è returns value 1
Dit is geen kwestie van wat is beter of slechter, maar eerder een kwestie van wat is nodig voor de applicatie/business. Wanneer we aan partition switching gaan denken, en vooral met het doel om data te archiveren, moet er goed bekeken worden welke data gerelateerd aan de partition key we al dan niet in de te archiveren partition willen zien staan. Willen we bijvoorbeeld partitioneren op dag, willen we dan de data van die dag in de te archiveren partition, of de data ouder dan de gespecifieerde dag?
De partitie functie bepaalt aan de hand van de partitie key hoe een tabel zal gepartitioneerd worden. Partition key is zowat het belangrijkste onderdeel omdat deze zal bepalen of query engine partitie eliminatie kan toepassen of niet. De gepartitioneerde tabel wordt gecreëerd in het partitie schema dat op z’n beurt de partitie functie gebruikt om de partities te verdelen over eventueel meerdere fysische files. Range Left en Range right bepalen waar de grenswaarden komen en worden vooral bepaald door de aard van de toepassing.

Crafted by ![]()
Crafted by ![]()





