



As BI consultants we regularly get the question to load one or more Excel files. Files tend to have different layouts, almost always consist of multiple worksheets and columns often contain different data types, making it more complex to load an Excel file than it would initially appear. After lots of #$@&%*! I grew tired of being frustrated, so I started looking for a solution that would simplify loading intricate Excel files. Here’s what I came up with.
First of all, I always write data in a reusable table such as the one below:
CREATE TABLE ExcelDataLoad(
[Id] INT IDENTITY NOT NULL,
[FileName] NVARCHAR(250) NOT NULL,
[SheetName] NVARCHAR(250) NOT NULL,
[Column1] NVARCHAR(250),
[Column2] NVARCHAR(250),
[Column3] NVARCHAR(250),
[Column4] NVARCHAR(250),
[Column5] NVARCHAR(250),
[Column6] NVARCHAR(250),
[Column7] NVARCHAR(250),
[Column8] NVARCHAR(250),
[Column9] NVARCHAR(250),
[Column10] NVARCHAR(250),
[Column11] NVARCHAR(250),
[Column12] NVARCHAR(250),
[Column13] NVARCHAR(250),
[Column14] NVARCHAR(250),
[Column15] NVARCHAR(250),
[Column16] NVARCHAR(250),
[Column17] NVARCHAR(250),
[Column18] NVARCHAR(250),
[Column19] NVARCHAR(250),
[Column20] NVARCHAR(250),
CONSTRAINT PK_ExcelDataLoad PRIMARY KEY (Id)
)
Loading data into this type of table allows me to comfortably edit it: cleaning, converting, mapping, transforming, etc. This kind of table also brings some difficulties:
To overcome this, I came up with one package that reads all Excel files at once. This way I can transform the data afterwards in other packages or specific stored procedures.
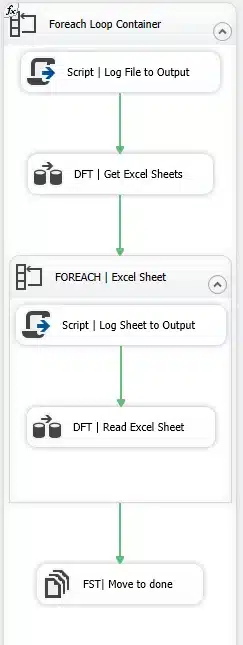
Step 1: I started with adding a first ‘foreach’ loop. Then I set up a parameter with a data directory, enabling it to loop over all the Excel files in that directory.
Step 2: Logging is not really necessary, but I prefer keeping a record of which file I’m processing in my SSIS output.
Step 3: Read the available Excel worksheets.
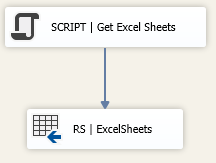
The following script reads the Excel file and adds the names of each worksheet in our data flow. Then we write all this data to a RecordSet that we can use later on.
string excelFile = Variables.DataDirectory + Variables.FileName;
string connString = "Data Source = " + excelFile + "; Provider = Microsoft.ACE.OLEDB.12.0; Extended Properties = \"Excel 8.0;HDR=NO;Imex=1;ImportMixedTypes=Text;\"";
OleDbConnection objConn = null;
DataTable dt = null;
try
{
objConn = new OleDbConnection(connString);
objConn.Open();
dt = objConn.GetOleDbSchemaTable(OleDbSchemaGuid.Tables, null);
if(dt != null)
{
foreach(DataRow row in dt.Rows)
{
Output0Buffer.AddRow();
Output0Buffer.SheetName = row["TABLE_NAME"].ToString();
}
}
}catch(Exception ex)
{
//do nothing
}
finally
{
if(objConn != null)
{
objConn.Close();
objConn.Dispose();
}
if(dt != null)
{
dt.Dispose();
}
}
Step 4: We add another ‘foreach’ loop that will iterate over all the available worksheets.
Step 5: Logging again is not necessary, but here I keep track of which sheet I’m processing.
Step 6: This is the most important one! Instead of using an Excel File Source, we need to use a Script Source, with as OutputBuffer the maximum number of columns that you could ever get. Of course you need to make sure that your destination table has the same number of columns.
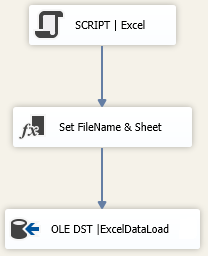
The following script is the most interesting of this blog:
String sheetName = Variables.SheetName;
string excelFile = Variables.DataDirectory + Variables.FileName;
string connString = "Data Source = " + excelFile + "; Provider = Microsoft.ACE.OLEDB.12.0; Extended Properties = \"Excel 8.0;HDR=NO;Imex=1;ImportMixedTypes=Text;\"";
OleDbConnection objConn = null;
OleDbCommand objComm = null;
OleDbDataReader rdr = null;
try
{
objConn = new OleDbConnection(connString);
objConn.Open();
objComm = objConn.CreateCommand();
objComm.CommandText = "SELECT * FROM [" + sheetName + "]";
rdr = objComm.ExecuteReader();
while (rdr.Read())
{
if(rdr.FieldCount > 0)
{
Output0Buffer.AddRow();
int i = 0;
while (i < rdr.FieldCount)
{
if(Output0Buffer.GetType().GetProperty("Column" + (i + 1).ToString()) != null) //if column exists in outputbuffer
{
Output0Buffer.GetType().GetProperty("Column" + (i + 1).ToString()).SetValue(Output0Buffer, rdr[i].ToString());
}
i++;
}
}
}
}
catch (Exception ex)
{
//do nothing
}
finally
{
if(rdr != null)
{
rdr.Close();
}
if(objComm != null)
{
objComm.Dispose();
}
if (objConn != null)
{
objConn.Close();
objConn.Dispose();
}
}
The above set of code opens a connection to the Excel file. I SELECT * from the worksheet that I am currently processing and check how many columns are available for each row (in the OleDbDataReader) (dr.Read()) If there are more than 0 columns, then I continue and create a new row in the dataflow. Next, I want to iterate over each column of that row. To do this, I check if the column that I want to fill exists in the OutputBuffer. If so, I can fill this column with a certain cell value I’ve selected (Column/Row combination). Instead of Output0Buffer.Column1 = some_value, this script does it dynamically. This way it does not matter how many columns there are, unused columns will be displayed as NULL.
I made use of OLEDB. This allows me to close the connection myself and not get a locked file. By using ExtendedProperties in the ConnectionString, I don’t easily get issues with wrong datatypes. Finally, thanks to the above script I can read any Excel file with any structure. Of course this SSIS Package might need some changes, depending on which requirements you have. Personally, however, I think it’s a good basis to start with. I hope this blogpost was helpful to you and that you can use it now or anywhere in the future.

Crafted by ![]()
Crafted by ![]()





