



When I started to jump from DBA to Data Architect, I thought that these roles would diverge further and further until they became two separate roles and functions. Both with their own skillset and their own purpose in the (big) Data Analytics world. The current evolution Microsoft launched proved me wrong though. Enter Azure Synapse Analytics.
Azure Synapse is Azure SQL Data Warehouse evolved—blending Spark, big data, data warehousing, and data integration into a single service on top of Azure Data Lake Storage for end-to-end analytics at cloud scale.
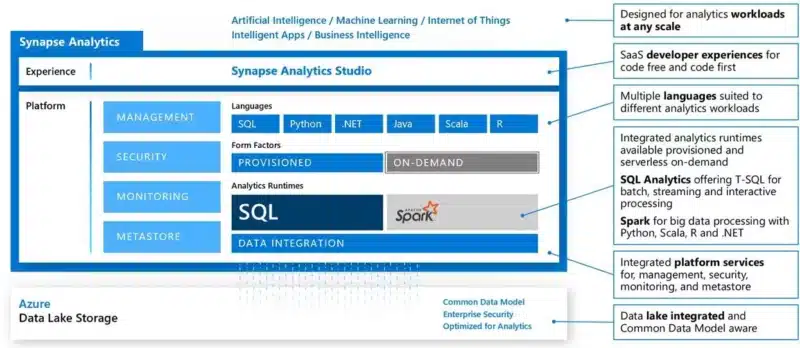
Due to the power of this platform it naturally blends with all the existing connected services like the Azure Data Catalog, Azure Databricks, Azure HDInsight, Azure Machine Learning and of course Power BI.
The improvements of the Azure Gen 2 components, provide benefits that require no configuration and are provided out-of-the-box for every data warehouse these improvements include the non-volatile memory solid-state drives to increase the I/O bandwidth available to queries, Azure FPGA-accelerated networking enhancements that enables the environment to move data at rates of up to 1GB/sec per node to improve queries. This improves the Azure Datawarehouse’s inherent possibility to leverage the multi-core parallelism in the underlying SQL Servers allowing it to move data efficiently between compute nodes while ongoing investments in distributed query optimization will also greatly improve the systems performance over time.
Out of the box Azure Synapse Analytics has more then 90 connectors and can sustain ingestions of up to 4GB/s, and more importantly the big data formats like CSV, AVRO, ORC, Parquet and JSON files. This is the complete stack of Azure Data Factory
To enable a graphic, code free graphical interface the platform uses ADF Data flow for it’s data integration providing it with seamless integration into an existing Azure Data Platform.
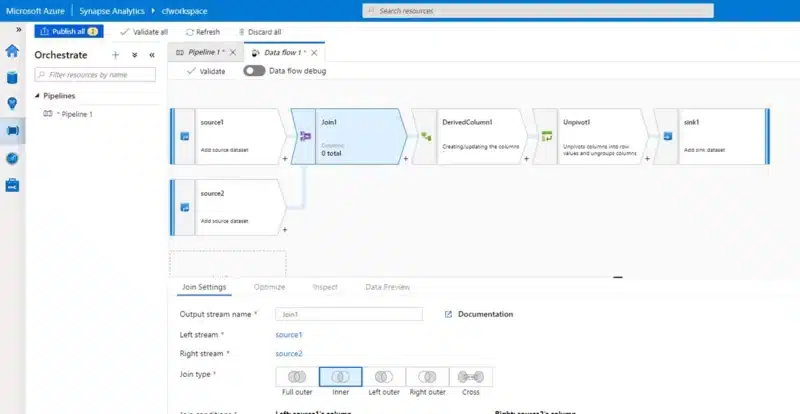
This combined with wrangling data flows. This will enable the platform to create compete ETL & ELT flows from a graphical interface, taking away the complexity of spark code where it isn’t needed.
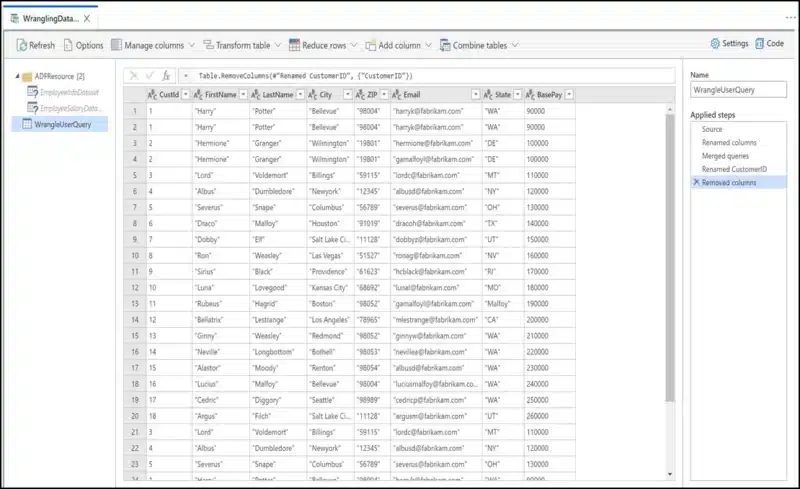
This makes the tool extremely useful for generic loads that don’t need specialized logic or have complex data flows.
Here is where (for me) the real synergy starts, this is where you can use the power of Spark where it can really shine, without having to suffer from its drawbacks. Spark is extremely powerful with large complex dynamic data flows. Code that would be a lot harder with ADF to create. But has a large overhead where it’s power cannot be put to full use.

Spark can also provide extra power in the analytics department where spark’s superior analytics feature can greatly enhance Azure’s DWH analytical abilities. While The Azure DWH’s SQL is a really powerful language it sometimes has troubles with specific operations like removing duplicates or window functions that lean heavily on the master node. This is the kind of workload that can easily be done by Spark. Spark is also better suited for more advanced computational workloads like switching between data models and or business rules then core SQL. While SQL is much more mature on recomposing the data into workable datasets for reporting.


I from my side am looking really forward to the new possibilities of this platform!

Crafted by ![]()
Crafted by ![]()





