



Azure Data Factory (ADF) is a cloud-based Extract-Transform-Load (ETL) and data integration service. It allows you to create data-driven workflows for orchestrating data movement and transforming data at scale. Through a simple drag-and-drop interface the tool ensures that processes are easy to maintain. In most cases programming is not needed. In the rare situations where programming is necessary, you have some options to get the job done with the most popular one being Databricks notebooks. However, there’s another option that, in my opinion, deserves the same amount of attention: Azure Batch Service (ABS). In this blogpost, we’ll have a look at this service and see what it can do in an ADF pipeline.
I’m not really good at writing clear descriptions (or maybe I’m just lazy). So I had a look at the Microsoft documentation. Azure Batch runs large-scale applications efficiently in the cloud. It can schedule compute-intensive tasks and dynamically adjust resources for your solution without managing infrastructure. So, we can just move some programs to the cloud without a lot of hassle or limitations. Sounds cool, right? But how do we do this?
To figure out how to use this tool, let’s start with a breakdown of Azure Batch in its main components. I’m not going to do a deep dive into the configuration of the service, but will only have a high level look at the key components: the batch account, jobs, tasks, pools and nodes. The overview is shown on the next image. In our case, we can think of Azure Data Factory as the client application. A short description of all the components can be found in Table 1.
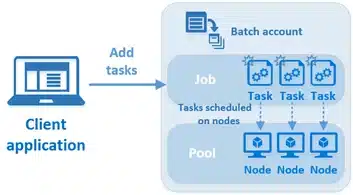
Figure 1: High level overview of Azure Batch Service
Table 1: Azure Batch Service key components explained.
| Job | The job manages a collection of tasks and is associated to a specific pool. |
| Task | A task is a unit of computation that is associated with a job. It runs on a node. Tasks are assigned to a node for execution, or are queued until a node becomes available. Put simply, a task runs one or more programs or scripts on a compute node to perform the work you need done. |
| Node | A node is an Azure virtual machine (VM) or cloud service VM that is dedicated to processing a portion of your application’s workload.
|
| Pools | A pool is the collection of nodes that your application runs on. Azure Batch pools build on top of the core Azure compute platform. They provide large-scale allocation, application installation, data distribution, health monitoring, and flexible adjustment (scaling) of the number of compute nodes within a pool. |
Azure Batch has some features that make it worth your while to use it. The first being that it is so powerful is that it can run any executable or script that is supported by the operating system of the node. Executables or scripts include *.exe, *.cmd, *.bat, *.py, *.ps1,… In this blog I’ll focus 100% on Python. Indeed Python again. I’m not going to lie, I’m a fanboy.
The second benefit is that you can choose the operating system when you create a pool. Azure provides some standard Linux and Windows images. But if this does not suffice, you can even bring in your own custom images.
Third, the pool you create can be automatically scaled by using formulas. This way new nodes can be added whenever there’s a lot of work to be done. At times when no tasks need to be executed, all nodes in the pool can be deallocated to reduce the cost. This is important since the underlying VMs are billed for the time they’re up, even when they’re idle.
A fourth reason to use Azure Batch is an interesting feature of its pools: the start task. With this functionality you can prepare the nodes in the pool to run the applications. The classic example is installing dependencies. The start task runs every time a node starts. This includes when the node is first added to the pool and when it is restarted or reimaged. When changes are made to the start task, it’s important to reboot the compute nodes for the start task to be applied.
Last but not least, pricing. Azure Batch itself is free, so you only have to pay for the resources that are used behind the scenes. When I did some testing, I checked the Cost Analysis of my resource group and was pleasantly surprised. The batch account costs were divided across multiple services, namely: virtual machines, load balancer, virtual network, storage and bandwidth. Seeing as the tool offers some features to limit the cost of these resources such as autoscaling the pool, you’re not racking up a sky high bill. But more on that later.
That’s it for the intro: Time to get our hands dirty!
I started using Azure Batch during the setup of a Proof-of-Concept. During the project someone asked me if it was possible to copy data from multiple tables spread across multiple databases to a destination database. Seeing as this task needed to be done in Azure Data Factory, it had to be completed in a single activity. So I started writing a Python script and tested it on-prem. This didn’t take long and worked very well. Next, I started to look for ways to integrate that script in Azure Data Factory. This brought me to Azure Batch Service. I had never used the service before, so started playing around with it. In the next sections, I’ll briefly describe some of my experiments.
To start this experiment, I created a new resource group containing the following:
During this first step, I did not yet add a storage account.
For the pool allocation mode, I chose the default (Batch Service). You can also choose User Subscription as a mode, but this is not advised in most cases. The difference is explained below.
| 1 | Batch Service (default) | Pools are allocated behind the scenes in Azure-managed subscriptions. |
| 2 | User Subscription | Batch VMs and other resources are created directly in your subscription when a pool is created. |
The selected option has an impact on which quotas are used during the pool creation. In the Batch Service mode, the quotas from within Azure Batch are used. In the User Subscription mode, the quotas from your subscription are used. This is important for the selection of the VM size during the pool creation as we will see in the next steps.
As a final step in the resource creation process, I set up one SQL Server instance with two serverless databases for testing. One database contained the sample ‘AdventureWorks’ dataset the other one did not contain any data. I used only one source database to limit the amount of resources.
In the previous step, we created our Azure Batch account with Batch Service as pool allocation mode. Before we jump directly to the pool configuration, let’s first check the quotas. This can be done by opening your batch account in the portal and going to Settings → Quotas. Here you can find the total dedicated vCPU limit and the limit per VM series type. For this demo, I would like to use A series VMs. As you can see on the image below, I can only proceed with the Av2 series.

Figure 2: Azure Batch Service Quotas
Now that we know which VM sizes we can use, it’s time to build the pool. You can create a new pool by going to Features → Pools. I created an Ubuntu Server pool with one node. The configuration details are shown below.
Table 2: Creation of the Azure Batch Service Pool
| Pool Detail | Pool ID | < choose a unique name > |
| Operating System | Image Type | Marketplace |
| Publisher | Canonical | |
| Offer | Ubuntuserver | |
| Sku | 18.04-lts | |
| Node Size | VM size* | Standard A1_v2 (1 vCPU, 2GB Memory) |
| Scale | Mode** | Fixed |
| Target dedicated nodes | 1 | |
| Target low-priority nodes | 0 | |
| Resize timeout | 15 minutes | |
| Start task | Start task *** | Disabled |
| Optional settings | / | / |
| Virtual network | / | / |
* see the quotas for the Azure Batch resource!
** The node will keep on running until the pool is manually rescaled. We will automate this later on.
*** We’ll configure the start task later in the process.
Now that the pool is created, we can start configuring it. But first, let’s link a storage account to the batch account. This will come in handy when we start defining our start task.
To do this open the batch account in Azure portal and go to Settings → Storage account. Select the storage account that you want to link, choose the authentication method and that’s it. Within the storage account, I created a container named batch-start-task. I’ll use this container to store all the files needed by the start task, but more on that later.
Our storage account is linked. So, time to go back to the configuration of the pool and more specifically the start task. In the batch account resource go to Features → Pools. Next, select your pool and go to Settings → Start Task. Here you can configure the start task for all the nodes within the pool. I used the following settings:
Table 3: Configuration of the Azure Batch Service Pool
| Max task retry count | 1 |
| Command line | /bin/bash -c “sudo apt-get update && sudo apt-get install -y python3 && sudo apt-get install -y python3-pip && sudo apt-get install -y unzip && sudo apt-get install -y unixodbc-dev && sudo -H pip3 install -r requirements.txt &&sudo curl https://packages.microsoft.com/keys/microsoft.asc | apt-key add – && sudo curl https://packages.microsoft.com/config/ubuntu/18.04/prod.list > /etc/apt/sources.list.d/mssql-release.list && sudo apt-get update && sudo ACCEPT_EULA=Y apt-get install -y msodbcsql17 “ |
| Wait for success | True |
| Use identity | Pool autouser, Admin |
| Resource files | – Resource file type: Auto storage container name – Value: batch-start-task |
* requirements.txt file is added to the batch-start-task container in the linked storage account.
As you can see, I installed Python3 to run the script and pip3 to install the Python packages. I also added the unzip tool. This is important since we will be uploading the scripts as zip files to our blob storage. Once we want to start the script, we’ll extract the content of the zip file to the working directory of the virtual machine.
I use zip files because most of my scripts contain a folder structure. If we just recreate the folder structure in the blob storage, we’ll have an issue because all the files will just land in the working directory when pushed towards the node. The folder structure will be lost and the script will not work correctly.
Next, I installed all the Python packages with pip3 by looking at the requirements.txt file from the batch-start-task container in the linked storage account. This file was created by using pip freeze in my virtual environment of Python.
Lastly, I installed the ODBC drivers for SQL server. Looking at the start task, this might seem rather complex, but in fact it’s pretty well documented in the Microsoft documentation. More information can be found here.
Now you might be wondering how I tested this command in the first place. Again, it’s pretty easy. When you go to General → Nodes from within your pool. You get a list of all the nodes. On the right side, you can click on the three dots and choose the option ‘connect’. From here you can connect to the node via SSH with a tool like Putty. This way it’s easy to test the commands.
The start task is configured. The only thing left to do is rebooting the nodes to apply the changes and we’re good to go.
When I created the pool, I chose a fixed scale. This means that the same amount of nodes will remain available whole the time. This is not a cost-effective way of working since virtual machines are billed for the time they’re running.
Time to make scaling a bit more dynamic. Head over to the batch account in the Azure Portal. Then go to Features → Pools and select your pool. Afterwards, go to Settings → Scale and change the mode from Fixed to Auto Scale. Here you can configure the evaluation interval (min: 5 minutes, max 168 hours) and enter the scaling formula.
I tested two ways of autoscaling. First, I tried autoscaling based on a fixed schedule. Second, I tried scaling based on the number of pending tasks. In both tests I used an evaluation interval of 5 minutes.
In my test, the pool was scaled to one node from Monday to Friday between 6:00 and 7:00 UTC time. Outside this timeframe all nodes were deallocated. I chose ‘taskcompletion’ as deallocation mode to ensure that tasks are ended before the node shut down. The configuration of my first test is shown below:
Table 4: Configuration of Autoscaling Formula (Fixed Schedule)
| Mode | Auto scale |
| AutoScale evaluation interval | 5 |
| Formula | $Now=time(); $WorkHours=$Now.hour>=6 && $Now.hour<7; $IsWeekday=$Now.weekday>=1 && $Now.weekday<=5; $IsWorkingWeekdayHour=$WorkHours && $IsWeekday; $TargetDedicated=$IsWorkingWeekdayHour?1:0; $NodeDeallocationOption = taskcompletion; |
After saving the auto scale formula, you see an evaluate button. When you press this, you get a list of all the variables with their current value. As can you see, at the time of evaluation no nodes were started, since $TargetDedicatedNodes and $TargetLowPriorityNodes were both 0.
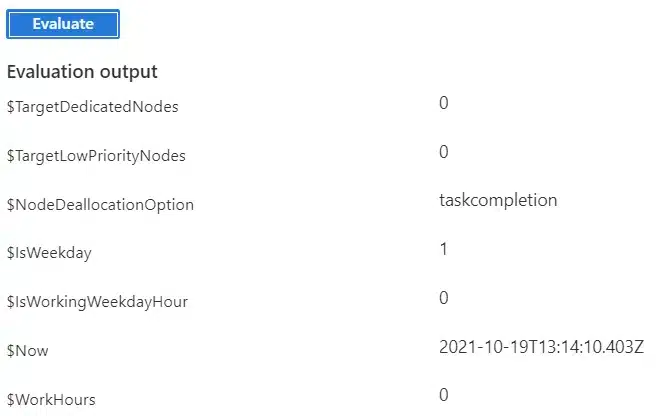
Figure 3: Azure Batch Service – Pool – Auto Scale (Fixed Schedule)
Another way to autoscale the pool is by looking at the number of pending tasks. I tested a formula that checks the last sample of pending tasks that Azure Batch retrieved. If this is 0, the number of nodes in the pool is reduced to 0. Else one node is created. For the node deallocation option I chose ‘taskcompletion’ again.
Table 5: Configuration of Autoscaling Formula (Number of pending tasks)
| Mode | Auto scale |
| AutoScale evaluation interval | 5 |
| Formula | $LastSampledPendingTasks = $PendingTasks.GetSample(1); $needcompute = min($LastSampledPendingTasks,1); $TargetDedicated = $needcompute ? 1 : 0; $NodeDeallocationOption = taskcompletion; |
The output for this formula is shown below.
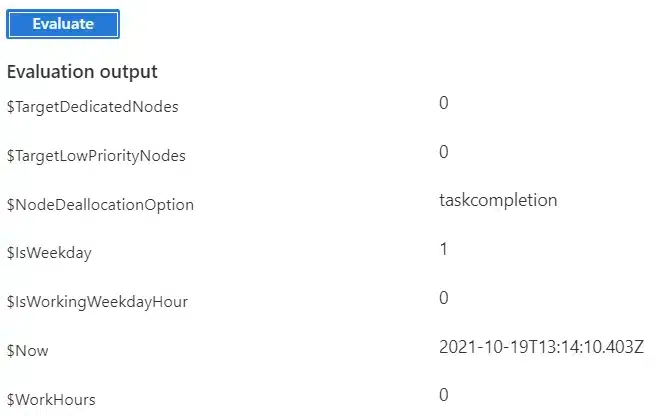
Figure 4: Azure Batch Service – Pool – Auto Scale (Number of pending tasks)
To test this, I started a pipeline with a custom activity in Azure Data Factory. This resulted in a pending task. Once the autoscaling function picked this up, it started creating a node. The pipeline kept waiting in the meantime. When the node was ready, the task was executed and the pipeline continued. After this there were no pending tasks left and the autoscaling function automatically deallocated the node.
While I only tested these two options, there’s much more that you can do with these formulas. If you want more detailed information, this is the place to start: https://docs.microsoft.com/en-us/azure/batch/batch-automatic-scaling
For both tests I have only been working with dedicated nodes. Low-priority VMs, however, are certainly also worth mentioning. They take advantage of surplus capacity in Azure, when available. They’re significantly cheaper, but may not always be available to be allocated. They can also be pre-empted at any time depending on the available capacity. More information about low-priority nodes can be found here: https://docs.microsoft.com/en-us/azure/batch/batch-low-pri-vms
With Azure Batch all configured and ready to go, let’s bring it to Azure Data Factory.
Figure 5: Result test run to transfer multiple tables from one DB to another using Azure Batch Service in Azure Data Factory
After running the pipeline, you can check the stdout.txt and stderr.txt log files in two places: on the node that processed the task or in a container created by ADF. Both logs are very useful for debugging. How long the task data is kept is determined by the retention time specified in your configuration. On the node this is seven days by default. Take into account that if the node is deallocated, the files will disappear as well. In the container created by ADF, the files will be kept for 30 days by default.
You can find the files on the node by opening your Batch account in Azure Portal and going to Features → Jobs. There you can select the job associated with the pool and click on a task to see the details. To find the files created by ADF, go to the storage account that is specified in the linked service. Here, you’ll see a container named adfjobs. Seperate folders are created for each task in this container.
Our little test worked. Whoop whoop! But there are still so many cool things to try. I’ll briefly mention a couple of them here.
What makes ADF such a great tool are parameters and variables. There’s often confusion about which is what, so let me clarify. Simply put, parameters are external values passed into pipelines. They can’t be changed inside a pipeline. Variables, on the other hand, are internal values that live inside a pipeline and can be adjusted inside that pipeline. With these two options, you can make your pipelines, datasets, linked services and data flows dynamic, allowing you to create reusable objects.
These parameters and variables can be passed on to the custom activity to make the command dynamic. One example I tested is using a variable to choose which Python script to start inside the custom activity. I used the following formula to achieve this.

Figure 6: Formula to dynamically start Python script in ADF Custom Activity
The location to the resource folder path can also be made dynamic, just like the extended properties. But we’ll have a deeper look at the last one in the next paragraph.
As we’ve hinted in the previous paragraph, there are a couple of ways to get the parameters or variables from ADF inside your Python script. The first option is using command line arguments and the python argparse library. Another approach is using the extended properties from the custom activity object. With extended properties you can pass key/value pairs to a file named activity.json. This file is then deployed to the execution folder of your script. Next, the values can be made dynamic in Azure Data Factory. In my test, I used some system variables to do this. The result is shown below.

Figure 7: Azure Data Factory Custom Activity – pass parameters or variables to the Python script using argparse and extended properties
With Azure Data Factory, you can send custom values from within your script to the output of the custom activity. To do this you simply create a json-file named outputs.json from within your Python script. The service copies the content of outputs.json and appends it into the Activity Output as the value of the customOutput property. The size limit is 2MB. If you want to consume the content of outputs.json in downstream activities, you can get the value by using the expression @activity(‘<MyCustomActivity>’).output.customOutput. An example is shown below.
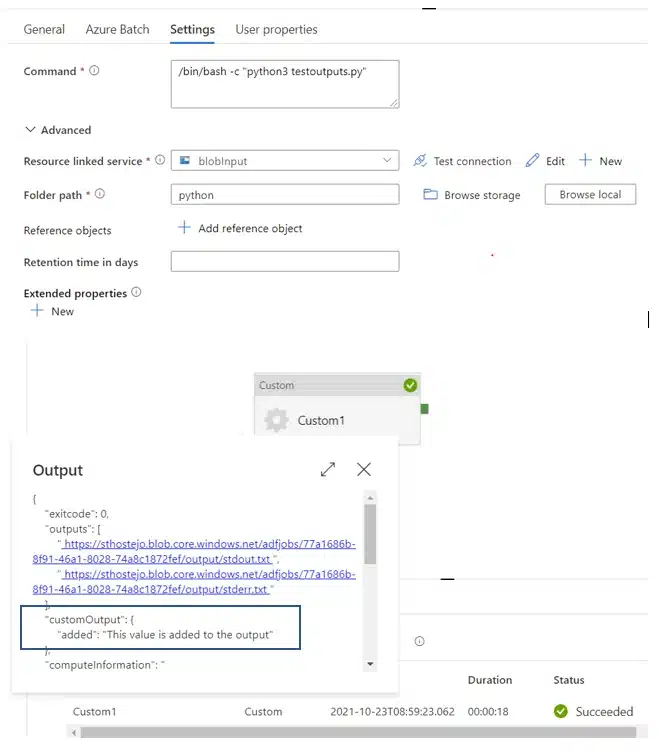
Figure 8: Azure Data Factory Custom Activity – add something to the output from within the Python script
After playing with the scaling formulas, I did some quick tests with the azure-batch Python library. This is again something really cool and useful to have a look at. This library allows you to make changes to the configuration of your Batch account with just a few lines of code. I made an Azure Function to add/remove nodes from my pool and made a new ADF pipeline to do some testing. The first step in the pipeline was an Azure Function task that ensured a node was running before the custom activity was initiated. The last step of the pipeline was another Azure Function task that deallocates the node(s). The result looked like this:

Figure 9: Scale Azure Batch Pool with Azure Functions
The documentation of the azure-batch Python library can be found here.
This was my first exploration of Azure Batch. It’s a very powerful tool to run large scale applications on Azure. You can completely configure the service to your needs. For instance, you’re free to choose the OS on the virtual machines. Scaling is also straightforward. Horizontal scaling can be done with the automatic scaling feature. This will add or remove nodes from the pool based on a formula. Of course, it can also be done manually. Vertical scaling can only be done by creating a new pool with a different node size. Preparing the VMs to run the applications can be done using start tasks.
In short, Azure Batch Service makes it a pleasure to bring Python applications to Azure. But it’s not limited to that. You can use it for exes, PowerShell scripts, and much more. It all depends on the configuration of your VMs. On top of that, it’s very easy to integrate with Azure Data Factory. You can simply start a task with a custom activity. It’s also easy to get some variables in and out of the custom activity.
I hope you are as impressed by Azure Batch as me and that you might give it a shot in one of your next projects. I added some links in the next section to help you get started.
Want to learn more? Take a look at our other blog articles!






