



Example file: No better way to understand this blog post then to do it yourself. You can download the SSIS package here. It also contains a task to (re)create the DB, but this will take about ten minutes to complete, so if you prefer, you can download the DB-backup here. In SSIS, change the variable `ServerName` with your server\instance.
Did you ever needed to use a lookup in SSIS that was not the standard equi-join and there was no possibility to do the lookup directly in the source?
A situation that you might have encountered before is when you get a date and you need to find a value in a reference table based on that date, but there’s no one-to-one match, as the reference table contains start and end dates, so a match is defined as a date that lies between these start and end dates.
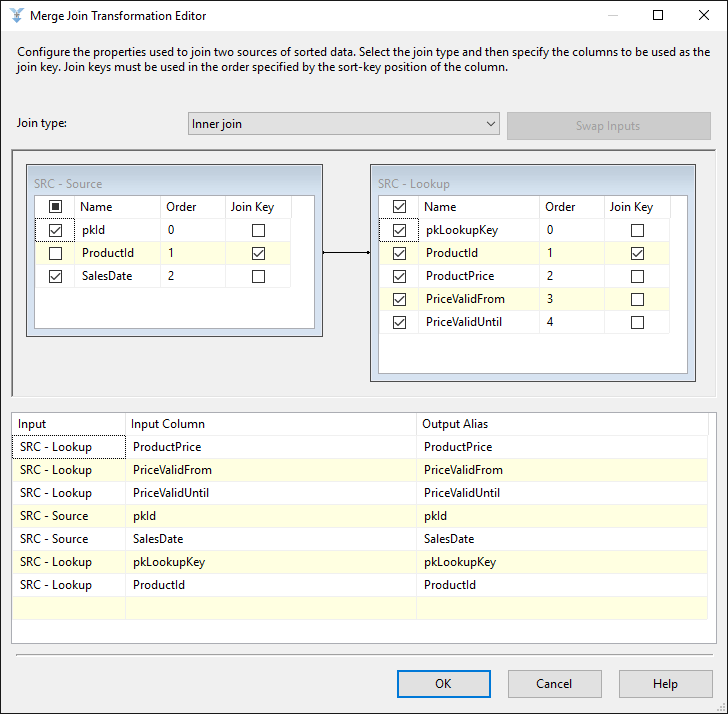
In the following example the DmKey’s in the Source Table need to be found by a matching record in the Lookup Table:
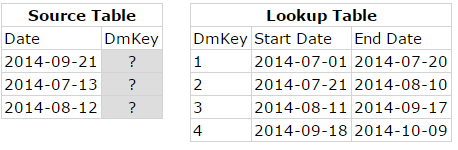
The following tables illustrate the matching records with corresponding colors:
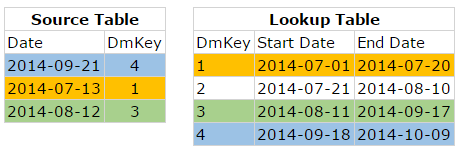
But how can you find these matching records with the help of SSIS?
There is more than one solution to this problem, some actually being independent from SSIS. In this blogpost we will compare four different solutions:
Doing the lookup directly in the source – SQL JOIN – might seem the fastest way, however this is not always possible. But I included this option in the comparison as it looked like a nice base to compare the other solutions with.
Besides a JOIN at the source, you could also create a derived helper table based on the lookup table with dates and keys so there’s no ambiguity left and a one-to-one match is possible. Such a table would look like this:
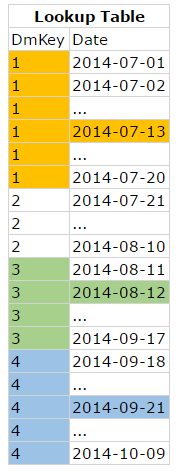
All dates from start to end date will then become separate records, with the same DmKey per range. But chances are big that it will produce a table with an enormous amount of records, not to mention that you need to incorporate the creation of the helper table in your ETL and so you might lose some time there as well (unless you can change the dimension permanently). Further on, this solution might not work that smooth or not at all when your conditions for a `match` are more complicated or when the source of the lookup table is, for example, provided as a flat file.
This option is not included in this post, but you can read more about it in Anthony Martin’s blog post. Now, let’s talk about the three solutions where SSIS can help us with a range lookup.
The lookup component in SSIS is focused on equi-joins (one value exactly equals another value – although multiple fields can be used to define a match):

You can however overrule the SQL statement in partial cache mode (or when using no cache at all). Doing so allows you to use the BETWEEN statement:
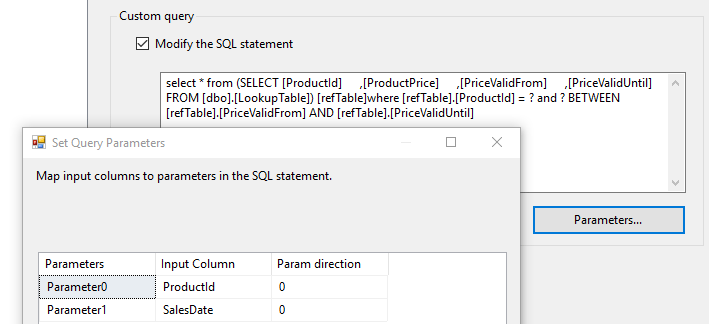
The downside is that you’re not able to use full caching, the one thing that makes your lookup component fast (in most cases at least). If your source table is very large it will result in a big performance degrade, as many database roundtrips will be made to the reference table. A colleague of mine wrote an excellent blog post on this topic.
So how can you mimic lookup’s in SSIS that do not use an equi-join, but do not hit so hard on the level of performance? Let’s talk about the Merge Join and the Script Component.
When the Merge Join solution was used to perform the lookup, it created 101.034.284 rows:
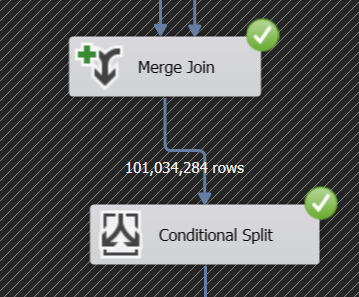
This huge amount of rows was further on filtered with the conditional split. Although this seems somewhat overkill, the results prove there’s a gigantic performance boost compared with the cache lookup (more than 3 times faster). Here are some more details about this particular Merge Join. Consult this package to go through all details:
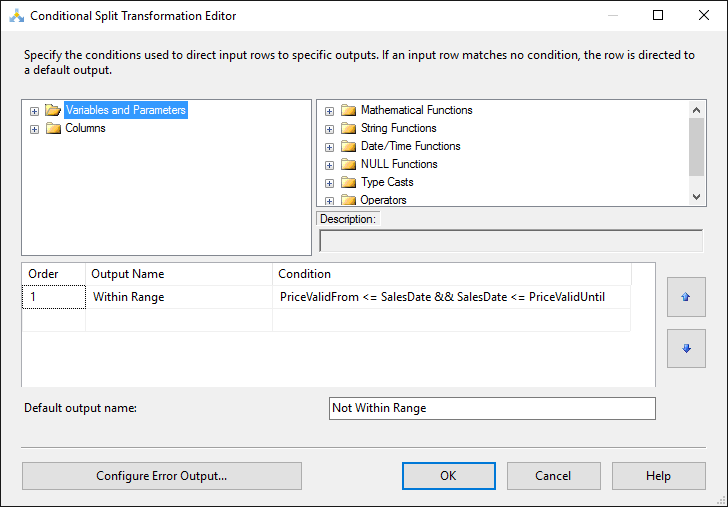
So we’re still far from the performance level that we have when the join is done at the source (which is less than 6 seconds in this particular setup). So in this final solution, we will use the Script Component in Transformation mode to do a lookup.
It was a combination of a situation at a client and Matt Masons blog that made me try this solution for the problem. When I read Matt’s blog, his source files were however not available on his blog anymore and so I started looking for my own solution, hence this blog post.
In a first step we will read the 5.000 records from the lookup table and create a class instance for each row. These class instances are collected in a Dictionary object. This is a process that goes very fast (unless your lookup table is extremely large). This way we actually cache the lookup table in a .NET object. In the next step, the source rows (1.000.000) are coming in and these records are also transformed to a class instance of the same type. These class instances are compared with the classes in the Dictionary. As this comparison goes very fast, we get spectacular results: we’re even faster than the lookup when it was done directly in the source (compare the results below)! This is the approach being followed:
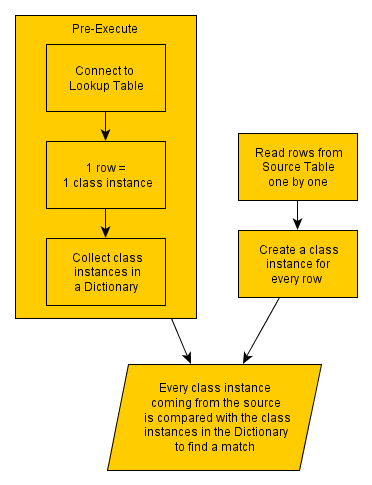
This is not an in-depth overview of the script component itself, but the following explanation will help you get up and running a little bit faster. When dragging the Script Component to the data flow you will be asked to choose how the script will be used, and you need to choose Transformation:
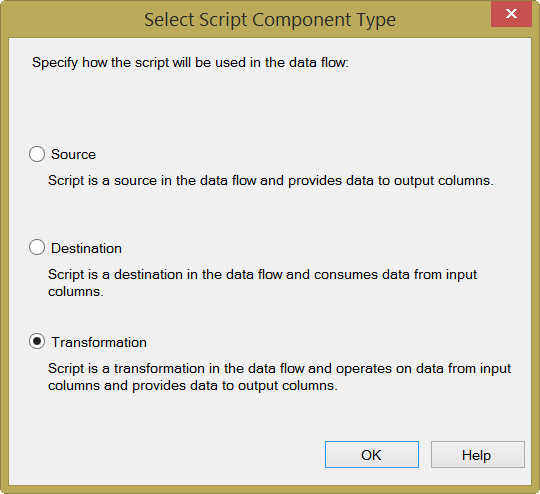
Provide the input columns: in this case we need the ProductId and the SalesDate:
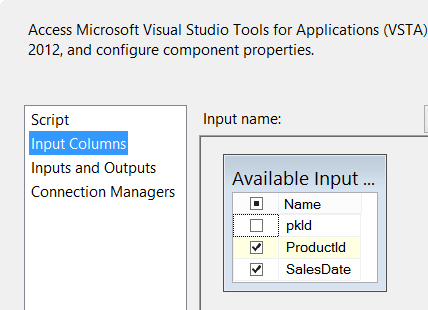
We’re looking for the price of the product, so we add the ProductPrice column as an output column (in a Data Warehouse, you might be more interested in the pkLookupKey coloumn, but the idea stays the same):
I also referenced an ADO.NET connection manager as it is used to build our lookup table in the script:
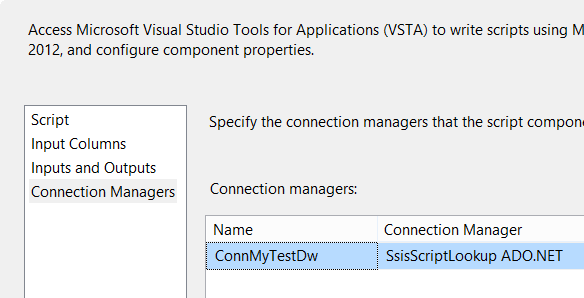
Now you can create the script. Be sure to check out the full script in the package (which you can download here). Let’s analyse the script step by step. These are the declared variables:
private IDTSConnectionManager100 connMgr;
private SqlConnection sqlConn;
private SqlCommand sqlCmd;
private Dictionary<Price, int> dPrices; // in System.Collections.Generic
As I’m trying to use connections that are defined in SSIS, I use the ADO.Net connection. This is done by overriding the method AcquireConnections:
public override void AcquireConnections(object Transaction)
{
connMgr = this.Connections.ConnMyTestDw;
sqlConn = (SqlConnection)connMgr.AcquireConnection(null);
}
Of course, if your reference table is provided as a flat file, your code will be different.At the end of the script you will see that a custom Class is created named Price. For now, let’s focus on its properties only (we’ll discuss its two methods afterwards):
public int ProductId { get; set; }
public int ProductPrice { get; set; }
public DateTime PriceValidFrom { get; set; }
public DateTime PriceValidUntil { get; set; }
public DateTime SalesDate { get; set; }
You can see that the properties are a mix of what you’d expect in the reference table (like PriceValidFrom) with properties from the source (like SalesDate). By using the same type of object we can do a very fast comparison (by using the Equals method of the Price class).
Within the PreExecute method, the reference data is first gathered with standard SQL and in the while loop, every row is transformed to a Price object and added to the Dictionary):
public override void PreExecute()
{ base.PreExecute();
dPrices = new Dictionary<Price, int>();
SqlDataReader rdr;
string query = @”SELECT pkLookupKey,
ProductId,
ProductPrice,
PriceValidFrom,
PriceValidUntil
FROM dbo.LookupTable”;
sqlCmd = new SqlCommand(query, sqlConn);
rdr = sqlCmd.ExecuteReader();
// every row coming from the lookup table is transformed to a Price object
// these Price objects are added to the Dictionary
while (rdr.Read())
{
Price p = new Price(int.Parse(rdr[“ProductId”].ToString()));
p.ProductPrice = int.Parse(rdr[“ProductPrice”].ToString());
p.PriceValidFrom = DateTime.Parse(rdr[“PriceValidFrom”].ToString());
p.PriceValidUntil = DateTime.Parse(rdr[“PriceValidUntil”].ToString());
dPrices.Add(p, int.Parse(rdr[“ProductPrice”].ToString()));
}
rdr.Close();
}
The Input0_ProcessInputRow method is where all the rows from the source are coming in:
public override void Input0_ProcessInputRow(Input0Buffer Row)
{
// for every row coming in from the SSIS flow another Price object is created
// only ProductId and SalesDate are of importance
Price p = new Price(Row.ProductId);
p.SalesDate = Row.SalesDate;
int value;
// try to find a matching object if (dPrices.TryGetValue(p, out value))
{
Row.ProductPrice = value;
}
}
The TryGetValue method will compare the object with the objects in the collection. If it finds a matching object, it will return the correspondign Product Price.There are two reasons why this all works very fast:
But why is it this fast? There are two methods that you need to look at in the Price object.
public bool Equals(Price pr)
{
return pr.ProductId == this.ProductId
&& (pr.SalesDate >= this.PriceValidFrom
&& pr.SalesDate <= this.PriceValidUntil);
}
The equals method works with the GetHashCode method. In certain conditions, the GetHashCode might return a hash code that already exists and then the Equals method can provide further logic to make sure if it’s equal or not.
public override int GetHashCode()
{
unchecked {
int hash = 13;
hash = (hash * 7) + ProductId.GetHashCode();
return hash;
}
}
If you look at our C# code, the GetHashCode method would not have been necessary as ProdutctId never is enough to get a unique object from our collection (every ProductId has multiple date ranges). But it’s such an important method that I did not wanted to leave it out. In my original case, at a client side, the comparison was a lot more complex: In 60% of the cases the ProductId was the only one in the lookup table. In the other 40%, there were multiple hits and the definition for a hit was very complex. By overriding the GetHashCode method, I was able to get a serious performance boost. You might want to read this community post to get an even better understanding of both methods.
Depending on the needs of the lookup, you can be creative and use some other .NET magic. In my case the actual question from the client, that led me to this solution, was an even more complex lookup, but the above, combined with a nested HashSet and some final Linq magic, did the trick (going from an ETL that took over 44 hours at first, to an ETL that did the job within an hour!).
These are the results of 20 cycles on my desktop (in the SSIS package, you can set the variable NrOfLoops to define the number of loops).The exact results will most likely be different on your machine, but proportionally the results should head in the same direction. I did run this on several machines and sometimes the Merge Join is somewhat faster, the SQL Join slower and the Lookup Script faster. But the order never changed (the Lookup Script was always the fastest of the four).
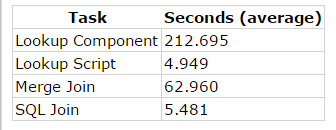
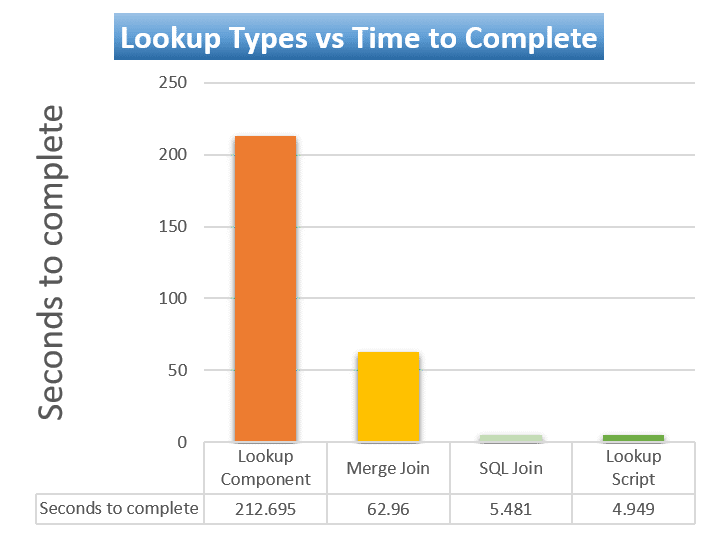
Using a script component to do a range lookup is not the easiest method around, but it definitely is the fastest method around. The hardest part is understanding why the Lookup Script is even faster than doing the join directly at the source. I have to leave this question unanswered. I’m sure that you can tweak some parameters at the level of SQL Server or with T-SQL, but nonetheless, the results are baffling and I hope you will get a serious performance boost when applying this method. It’s worth the effort!

Crafted by ![]()
Crafted by ![]()





