



SQL Server 2017 came with a couple of enhancements regarding Always On Availability Groups. For example, we can now specify the minimum number of secondary replicas that need to have written the transaction data to their log before the primary replica commits. But the most radical change came with the introduction of “Read-scale availability groups” or the support for Availability Groups without an underlying cluster.
Prior to SQL Server 2017, an Always On Availability Group required WSFC when running on Windows Server and Pacemaker when running on Linux. Over the past years I came across a couple of situations where this condition has proved to be a true blocking factor. The most first scenario that pops to mind is offloading data to multiple distributed servers where you need a readable copy for reporting purposes. This is where Read-Scale Availability groups enter the playground!
Naturally the absence of a cluster comes with a cost. To begin you must realize that clusterless AG’s should not be seen as a high availability or disaster recovery solution. It merely provides a new mechanism to synchronize databases across multiple servers. In traditional availability groups the cluster is responsible for the monitoring of the underlying infrastructure, detecting imminent failures and coordinating automatic failovers. Therefore, only manual failover without data loss and forced failover with data loss is possible when using Read-Scale availability groups.
Read-scale availability groups support read-only routing and thus by extension spreading the read-only workload using round-robin. This makes the technology perfect for the spreading of read-only workload across multiple secondary replica’s. Note though that since there is no cluster, you can only use the primary node’s IP address as a (dummy) listener. The reason for this is that normally the listener is a computer object in AD, maintained by the cluster as a cluster resource. This means that in case of a manual failover, you will need to drop and recreate the listener on your new primary replica. This proves again that Read-scale availability groups should not be seen as a HA or DR solution.
But enough of the theoretical chitchat, it’s time for some action!
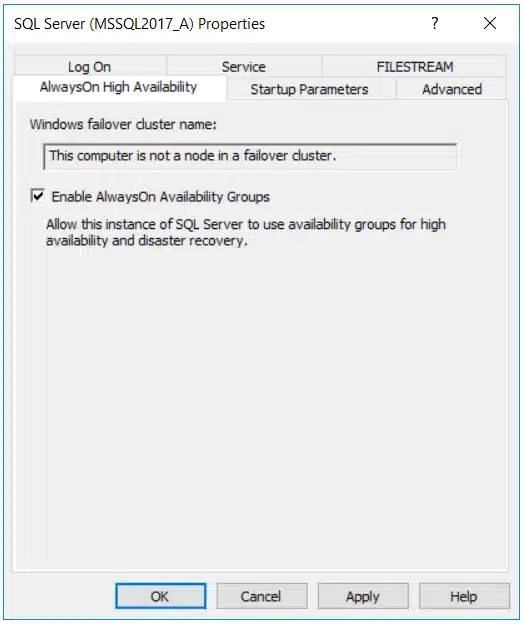
For my test I’ve set up two Windows Server 2016 VMs, both aren’t joined to any domain (I was lazy and I didn’t want to set up a domain, I used certificates instead 😊). Using the SQL Server Configuration Manager you must first enable the AG feature on all the instances you want to add to your AG. Since the machines aren’t joined to any cluster, it normally wouldn’t be possible to enable AG. But as you can see below, I managed to enabled AlwaysOn Availability Groups without any issue.
Next, use the following code to create your Read-Scale Availability Group, in my case ‘ClusterlessAG’. Notice the parameter ‘CLUSTER_TYPE’, you must set this to ‘NONE’. With this option you specify you wish to create the AG without an underlying WSFC or Pacemaker. Always set failover mode to manual, automatic failover is not possible since we don’t have a cluster.

Finally, join the secondary replica to the AG using the parameter ‘CLUSTER_TYPE = NONE‘. And now your Read-Scale Availability Group is finished!
Note: Since I used certificates I had to manually prepare the database and join it to the AG.
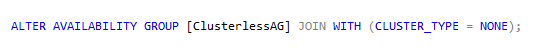
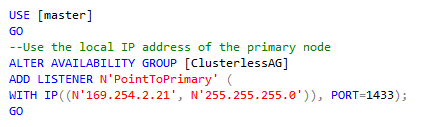
If you want to enable Read-Only routing you must first create a listener. Use the local IP address of your primary replica. You will not be able to use the listener, but it’s necessary to enable Read-Only routing. As mentioned before, when performing a manual failover, you must drop and recreate the listener using the local IP address of your new primary replica.
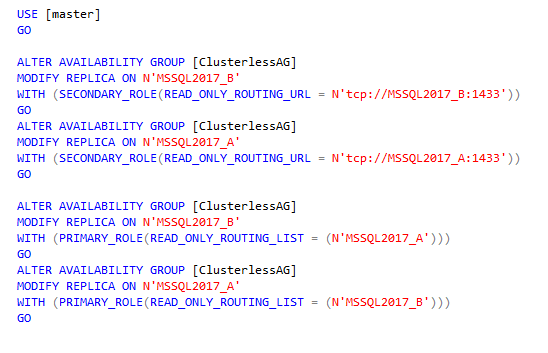
Finally create the routing URLs for both instances and specify the routing lists as you would do on a regular AG.
And that’s all there is folks! As you could see, it’s very straightforward to configure a Read-scale Availability Group. The most important thing to remember is that this technology wasn’t designed to be used as high availability or disaster recovery solution. But nevertheless, it’s a fantastic feature when used for its correct purpose!

Crafted by ![]()
Crafted by ![]()





