



APIs are one of the things we often come across when working with data. In this blogpost we’ll have a look at some ways of extracting data out of them with Python in an efficient way. For small amounts of data we could write a simple script that sends one request at a time. For large amounts of data this is no longer a recommended approach. Each response arrives with some latency. During this waiting period the script is idle. When we do a lot of requests, the total waiting time starts adding up. Retrieving all information in one big request is not a solution either since oftentimes this would result in timeout errors. We’ll need to tackle this problem in a different way. Luckily there are some options. We’ll have a look at three of them: threading, asyncio and multiprocessing. In our examples we’ll only use very basic GET-requests. For those who want to dive deeper into the requests library: check out the docs (link in further reading). Time for some action, but first let’s make sure that all the required software is installed.
A thread is a separate flow of execution. By using threads Python can handle multiple tasks concurrently. However, only one thread can run at a time due to interactions with the Global Interpreter lock (GIL). So threads will not speed up all tasks. They’re mostly useful for tasks that spend much of their time waiting like GUI’s and applications with a lot of I/O. For CPU intensive tasks it’s better to proceed with multiprocessing.
It’s also important to note that switching between threads is done by the operating system and can take place at any point in time. This makes it harder to debug threaded applications. Variables that are shared between threads could also cause race conditions when not properly implemented. This can be avoided by adding locking mechanisms. Choosing the appropriate lock granularity is not always easy however. Moreover adding locks could increase the risk of deadlocking. So working with threads always requires a certain amount of caution.
We want communication between our threads, but also want to stay away from manual lock configurations. This is the perfect scenario to bring in queues. This is a Python class that implements all the required locking semantics for you. We populate the queue from the main thread and start up some worker threads to process the queue items.
The same can be done with asyncio, but here the worker threads will be replaced by worker tasks. Easily put, tasks are wrappers for coroutines and coroutines are objects scheduled in the asyncio event loop. All tasks are processed in the same process and thread, but context switching is possible at places that you specify to reduce the idle time.
For multiprocessing the same flow can be applied. This time the worker threads will be replaced by worker processes.
The Queue/Worker-flow is visualized in Figure 1.
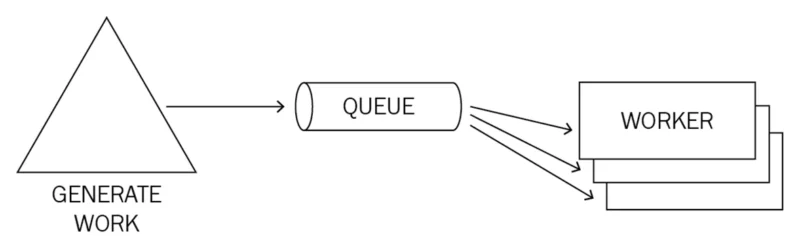
Figure 1: Queue/Worker-flow.
Work is generated and placed in a queue.
Multiple workers take items from the queue and process them.
We’ll implement the workers as separate threads, processes and asynchronous tasks.
We had a look at threading. But what is asyncio and why would it be useful in this case? Asyncio can be used to run a program asynchronously within one thread. The core of asyncio is the event loop. This loop keeps track of all the running tasks and wakes them up when needed. Tasks can be checked to see if they’re for example done or cancelled. A Task, in turn, wraps a Coroutine. This is the code that’s actually getting executed when a Task is activated.
The main difference with threading is that you choose when the program is allowed to switch to another task. This is done by setting checkpoints, recognizable by the keyword await. With threading switching is handled automatically by the operating system.
Implementing asyncio can be challenging at first but can make the application perform better while keeping debugging relatively easy. Another thing to keep in mind is that you need to use different libraries for asynchronous programming. For our API-requests we used aiohttp instead of requests.
Although this option is not recommended for CPU-inexpensive tasks with a lot of I/O, I’ll demonstrate it to show similarities and dissimilarities with the two previous options. With multi-processing the limitations of the GIL can be circumvented, what makes it the go-to solution for CPU expensive tasks. Multiprocessing gives each process its own Python interpreter and memory space. So this involves more overhead than threading. In this example you will also see that communication between the processes adds some complexity to the script due to the fact that our workers do not share memory by default.
To have full control, we first configure a mock API locally with Mockoon. This is a free opensource tool that can be downloaded from: https://mockoon.com/download/
1. Install and open the application
2. Add a new route named: inventory/:type to the demo API
3. Change the body to:
{
"id": "{{queryParam 'id'}}",
{{# switch (urlParam 'type')}}
{{# case 'products'}}
"name": "{{faker 'commerce.product'}}",
"price": "{{faker 'commerce.price'}} EUR",
"quantity": "{{faker 'random.number' 50}}"
{{/ case}}
{{# case 'materials'}}
"name": "{{faker 'commerce.productMaterial'}}",
"price": "{{faker 'commerce.price'}} EUR",
"quantity": "{{faker 'random.number' 50}}"
{{/ case}}
{{/ switch}}
}
4. Set a delay to make it all a bit more realistic. I’ve chosen a delay of 200 ms in this case.
5. Make sure that the response code is configured to 200. The python script checks the response code after each request before adding the output to the results.
The complete configuration is shown in figure 2.
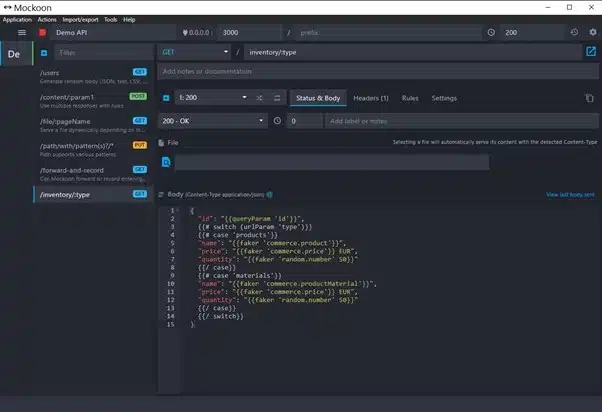
Figure 2: Mockoon API configuration for the example scripts.
Make sure that the server is started (press the play button) and test the API in the web browser by entering the following two URL’s. The results are shown in figure 3.
http://localhost:3000/inventory/materials?id=1
http://localhost:3000/inventory/products?id=1
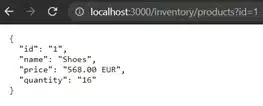
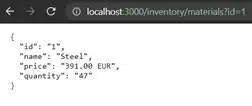
Figure 3: Mockoon – Test API responses for materials and products in web browser
The mock-API is running. Now we’re ready to start in Python.
First we’ll start with the threading example. 50 requests for materials and 50 requests for products are added to the queue. This queue is then processed by 3 workers that each have their own thread. Each worker consists of a while loop that continuously sends GET-requests to the API. A request session was opened before starting the loop to make sure that connection to the server stays open and configured for all the consecutive requests.
When the entire queue is processed all results are brought together in one dataframe. For all the failed requests the category and id are stored in a list. A set is created to store the unique combinations of worker id, process id and thread id. The code and results are shown below.
Result:
THREADING
WORKER 0: API request for cat: materials, id: 0 started ...
...
WORKER 2: API request for cat: products, id: 49 started ...
Dataframe (0 failed requests, 100 successful requests)
id name price quantity
0 2 Wooden 970.00 EUR 49
1 0 Metal 813.00 EUR 26
2 1 Frozen 387.00 EUR 28
3 3 Granite 537.00 EUR 12
4 4 Fresh 865.00 EUR 10
--- 9.845561742782593 seconds ---
['Worker: 1, PID: 17920, TID: 17488', 'Worker: 0, PID: 17920, TID: 19796', 'Worker: 2, PID: 17920, TID: 10608']
As you can see in the results, all workers ran under the same process id (PID). The thread id (TID) was different for each worker. You’ll see that increasing the number of workers will result in a lower runtime.
We do the same but this time the workers will be coroutines that are placed in an event loop. The code and results are shown below again:
Result:
ASYNCIO
TASK 0: API request for cat: materials, id: 0
...
TASK 0: API request for cat: products, id: 49
Dataframe (0 failed requests, 100 successful requests)
id name price quantity
0 0 Concrete 590.00 EUR 24
1 2 Soft 737.00 EUR 16
2 1 Rubber 637.00 EUR 33
3 3 Plastic 551.00 EUR 41
4 4 Granite 641.00 EUR 50
--- 9.883800745010376 seconds ---
['Task: 1, PID: 536, TID: 27600', 'Task: 0, PID: 536, TID: 27600', 'Task: 2, PID: 536, TID:27600']
This time all the workers (tasks) ran under the same process- and thread id. Increasing the number of tasks will again decrease the total runtime. In contrary to the threaded version this time we specified where context switching can take place by using the await keyword.
3.3. Python code example for multiprocessing
The last example shows the same flow but this time with multiprocessing. I wouldn’t recommend multiprocessing for this kind of application, but I just show it to complete the comparison. The code and results are shown below.
Result:
MULTIPROCESSING
WORKER 1: API request for cat: materials, id: 0 started ...
...
WORKER 1: API request for cat: products, id: 49 started ...
Dataframe (0 failed requests, 100 successful requests)
id name price quantity
0 0 Soft 153.00 EUR 17
1 1 Granite 732.00 EUR 42
2 2 Granite 893.00 EUR 39
3 3 Plastic 786.00 EUR 47
4 4 Cotton 260.00 EUR 43
--- 10.39824652671814 seconds ---
['Worker: 1, PID: 7116, TID: 21532', 'Worker: 0, PID: 28516, TID: 2228', 'Worker: 2, PID: 27424, TID: 21780']
Sharing objects between processes is a bit more difficult than in the previous examples. To realize this, I added a multiprocessing Manager to share lists between the worker processes. A set cannot be created via the Manager, so instead I created a dictionary and added the PID/TID/Worker combinations as key elements to get the same effect (only store the unique combinations of Worker ID, process id and thread id).
I used the JoinableQueue class from the multiprocessing library since the default Queue object from this package does not have the join or task_done methods.
As expected in the results we see that each worker has its own process- and thread id. The total runtime is also higher due to the extra overhead of multiprocessing.
All the sample scripts ended by returning a Pandas dataframe object. You can think of this as a Python equivalent for a spreadsheet. Just like in Excel, it’s very easy to apply transformations or make sub selections.
When the dataframe has the desired format, you can easily push it to its next destination. This can be an excel- or csv-file, a json- or xml-file, a database, the clipboard, markdown or html, …
The best part is that all of this can be done with a single instruction:
[DATAFRAME OBJECT].to_....(args)
For Power BI users there’s even more! Power BI allows you to use Python scripts as data source in PowerQuery. The dataframe produced by this script is converted to a table. All you need to do for this is
We had a look at three different ways of concurrency. Each with their advantages and disadvantages. Threading is good for CPU-inexpensive tasks with a lot of I/O or for building GUI’s. The biggest disadvantage is the lack of control for context switching which can make debugging harder, especially for larger applications.
Then we had a look at asyncio. This setup allowed to run tasks asynchronously within the same thread. The advantage here is the ability to specify where context switching can take place. The disadvantage is the added complexity for programming and the need for async libraries.
Lastly we had a look at multiprocessing, although this is actually used for CPU-expensive tasks and not for I/O-heavy tasks like our API-requests. Here we saw that it’s a bit more complex to share objects between processes. The total runtime was also bigger which suggests that there was more overhead than in the previous two methods.
That was the brief introduction by example. For those who wish to explore the subject further. Here are some good references to start with:
Want to learn more? Take a look at our other blog articles!

Crafted by ![]()
Crafted by ![]()





