



The most commonly created packages are data copy packaging from one source DB to a staging target DB. Instead of creating multiple packages (with or without BIML), a META data free solution can be made using the .NET SqlBulkCopy class. You can find the full description of this process in this blog. I’ll be giving an example of a staging process created with one single and easy package based on the package architecture.
We have one OLTP database with one reporting database. Report accuracy must not necessarily occur real-time, and can be refreshed hourly. The decision is made to copy the data each 30 minutes. So we’re planning a periodic SQL agent job to copy the data each 30 minutes using an SSIS package. The first time a full load will be copied, while all other loads must be an incremental load to minimize the data transfer and processing time. There’re a lot of tables in the schema that must be copied, where some have relational constraints, others not.
Knowing this, I will implement a standard SSIS package to do the job. Prerequisites for the implementation used:
All tables will be processed in the same manner in this example. Parameterizations for single tables is also possible, but not discussed here. First we’re setting up a parameter table for the process.
CREATE TABLE [dbo].[Processing](
[ID] [INT] IDENTITY(1,1) NOT NULL,
[GroupSequence] [INT] NOT NULL,
[ObjectSequence] [INT] NOT NULL,
[SourceObject] [VARCHAR](255) NOT NULL,
[SourceObjectType] [VARCHAR](50) NOT NULL,
[ProcessingDT] [DATETIME] NULL,
[InsertDT] [DATETIME] NOT NULL DEFAULT (GETDATE()),
[InsertedBy] [VARCHAR](255) NOT NULL DEFAULT (SUSER_SNAME()),
[UpdateDT] [DATETIME] NULL,
[UpdatedBy] [VARCHAR](255) NULL,
[StartedDT] [DATETIME] NULL,
[FinishedDT] [DATETIME] NULL,
[PrevProcessingDT] [DATETIME] NULL,
PRIMARY KEY CLUSTERED
(
[ID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, FILLFACTOR = 90) ON [PRIMARY]
) ON [PRIMARY]
Some fields need to be explained:
I’ve inserted the data already, a part of it:

The complete package :
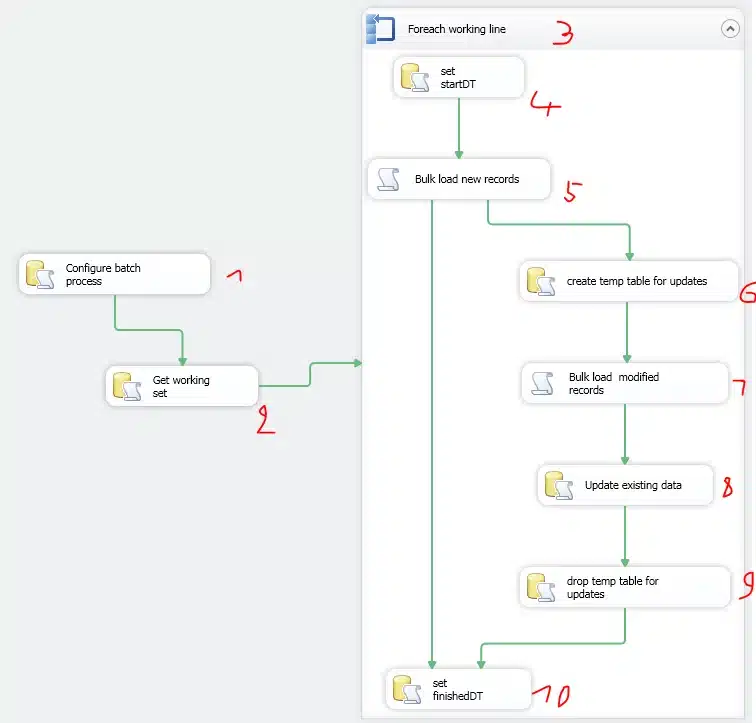
1. Initialize current iteration
Before starting the process, we need to check if the previous iteration was finished successfully. If not, we need to figure out where to restart to avoid repeating an already processed object. You really want to avoid doing the same thing over and over again when you have problems for one particular object. Using the extra field added to the ‘dbo.process’ table, we can do this quit easy with this query:
-- first run ever
IF(SELECT MAX(prevProcessingDT) FROM [dbo].[Processing]) IS NULL
UPDATE [dbo].[Processing] SET prevProcessingDT = '1900-01-01', ProcessingDT = GETDATE(), StartedDT=NULL, FinishedDT=NULL WHERE IsDeleted=0;
-- first run after reinitialize
IF(SELECT MAX(ProcessingDT) FROM [dbo].[Processing]) IS NULL
UPDATE [dbo].[Processing] SET ProcessingDT = GETDATE(), StartedDT=NULL, FinishedDT=NULL WHERE IsDeleted=0;
-- prev run completely done
IF (SELECT COUNT(*) - COUNT(finishedDT) FROM [dbo].[Processing]) = 0
UPDATE [dbo].[Processing] SET prevProcessingDT = ProcessingDT, ProcessingDT = GETDATE(), StartedDT=NULL, FinishedDT=NULL WHERE IsDeleted=0;
-- restart current run
-- do nothing
2. Select the object to process
This is in fact the most important part of the package. In this ‘execute SQL task’, you select the objects to process in the correct order regarding to the foreign key relations. For each object you select, the necessary parameters are created in the result table, so you don’t need complex variable expressions in the SSIS package. With this query, you determine the process workload.
;WITH cte_cols AS
(SELECT pro.id, pro.SourceObject, pro.GroupSequence, pro.ObjectSequence, pro.ProcessingDT, pro.PrevProcessingDT,
REPLACE(
CONVERT( VARCHAR(MAX)
,(SELECT c.name+','
FROM sys.tables t
INNER JOIN sys.columns c ON c.object_id=t.object_id
WHERE t.type='U'
AND '['+SCHEMA_NAME(t.schema_id)+'].['+t.name+']'=pro.SourceObject
ORDER BY c.column_id
FOR XML PATH(''), TYPE
)
)+','
,',,','') AS cols
,REPLACE(
CONVERT( VARCHAR(MAX)
,(SELECT 't.'+c.name+'=m.'+c.name+','
FROM sys.tables t
INNER JOIN sys.columns c ON c.object_id=t.object_id
WHERE t.type='U'
AND '['+SCHEMA_NAME(t.schema_id)+'].['+t.name+']'=pro.SourceObject
AND c.name NOT IN ('ID','InsertDT','InsertedBy')
ORDER BY c.column_id
FOR XML PATH(''), TYPE
)
)+','
,',,','') AS updcols
FROM [dbo].[Processing] pro
WHERE pro.SourceObjectType='Table'
AND FinishedDT IS NULL
)
SELECT id, GroupSequence, ObjectSequence, SourceObject
,'SELECT '+cols+' FROM '+SourceObject+' WHERE InsertDT > '''+CONVERT(VARCHAR(26),PrevProcessingDT,113)+''' AND InsertDT <='''+CONVERT(VARCHAR(26),ProcessingDT,113)+''';' AS newRecord
,'SELECT '+cols+' FROM '+SourceObject+' WHERE InsertDT <= '''+CONVERT(VARCHAR(26),ProcessingDT,113)+''' AND UpdateDT BETWEEN '''+CONVERT(VARCHAR(26),PrevProcessingDT,113)+''' AND '''+CONVERT(VARCHAR(26),ProcessingDT,113)+''';' AS modifiedRecord ,'SELECT '+cols+' INTO #WorkTable FROM '+SourceObject+' WHERE 1=0;' AS createTempTable ,'#WorkTable' AS TempTable ,'DROP TABLE #WorkTable;' AS dropTempTable ,'UPDATE t SET '+updcols+' FROM #workTable m INNER JOIN '+SourceObject+' t ON t.id=m.id '+';' AS updateStmt FROM cte_cols ORDER BY GroupSequence, ObjectSequence ;
The result of this is something similar as this partial output.

As you can see, all sql statements needed to process the object created and available in the package. Let’s show the statements for the ‘[dbo].[feature]’ table used in this example:
NewRecord statement to select all new records
SELECT ID , Name , InsertDT , UpdateDT , InsertedBy , UpdatedBy , IsActive , IsDeleted FROM [dbo].[Feature] WHERE InsertDT > '04 Oct 2016 14:08:01:513'
AND InsertDT <= '04 Oct 2016 14:18:39:233';
ModifiedRecord statement to select changed records after previous iteration
SELECT ID ,
Name ,
InsertDT ,
UpdateDT ,
InsertedBy ,
UpdatedBy ,
IsActive ,
IsDeleted
FROM [dbo].[Feature]
WHERE InsertDT <= '04 Oct 2016 14:18:39:233'
AND UpdateDT BETWEEN '04 Oct 2016 14:08:01:513'
AND '04 Oct 2016 14:18:39:233';
CreateTempTable statement to create the staging table on the target that will used as the input dataset for the update statement later.
SELECT ID ,
Name ,
InsertDT ,
UpdateDT ,
InsertedBy ,
UpdatedBy ,
IsActive ,
IsDeleted
INTO #WorkTable
FROM [dbo].[Feature]
WHERE 1 = 0;
DropTempTable statement to execute at the end
DROP TABLE #WorkTable;
UpdateStmt statement to update the target data
UPDATE t
SET t.Name = m.Name ,
t.UpdateDT = m.UpdateDT ,
t.UpdatedBy = m.UpdatedBy ,
t.IsActive = m.IsActive ,
t.IsDeleted = m.IsDeleted
FROM #workTable m
INNER JOIN [dbo].[Feature] t ON t.ID = m.ID;
Here you see the importance of the ID field.
3. Looping through the complete set
Now we have all the required process parameters and workload, we need to iterate over this output set. All other steps will process just one object from the workload data set. Result set is mapped using this definition:

4. Start processing the object
Tell the process where we are in the workload, and which object is handled next. The ‘execute SQL task’ updates the process table:
UPDATE [dbo].[Processing] SET StartedDT=GETDATE() WHERE ID=@id;
5. Bulk copy new records
This script which implements the SqlBulkCopy class uses this parameters:

6. Create temp table for updated records
Create the temp table using the sql prepared in the workload query:

7. Bulk copy modified records to temp table
The same script as before is used here to copy the changed records. Parameters passed to the script are:

8. Update the modified records
After the data is loaded into tempdb on the target server, we can do the update with this parameter:
![]()
9. Drop temp table
When the update is done, the temp table can be removed to recover the space by executing this statement:
![]()
10. Flag current object for completion
Finally update the processing table telling this object was finished successfully with this query:
UPDATE [dbo].[Processing]
SET FinishedDT=GETDATE()
WHERE ID=@id;
That’s it. No big surprised here, I guess. When you have this one package as a template package, the only thing you need to do is parameterize the ‘dbo.processing’ table and start copying.
Splitting the record set in two parts (new and modified records) can be removed, but this speeds up the process by limit the update dataset. Depending on the situation, you can tweak the process for the needs you have. I implement this a lot, because it takes no time to do and using this as a standard, makes it transparent for everyone in the organization as well.

Crafted by ![]()
Crafted by ![]()





