



Scenario: your customer has determined that your SSIS source for his new project is a CSV file with a header row followed by the data rows. All is developed and tests were made, all is success. After a few days of testing the customer wants the business user to have the ability to change the position of the data columns as the customer needs.
In this scenario BIDS 2008 was used. Later in this post I’ll discuss whether the same scenario is valid in SSDT 2010 or SSDT 2012. We created two input files named “DynamicPosition1.csv” and “DynamicPosition2.csv” with identical data. The only difference between the two files is that columns “Firstname” and “Country” switched positions.
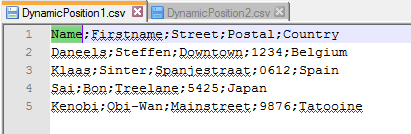
Figure 1: Inputfile 1
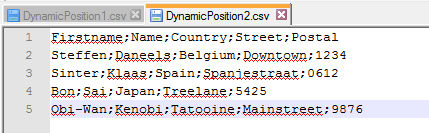
Figure 2: Inputfile 2
The outcome on using a normal Flat File Connection with the two input files.

Figure 3: Connection
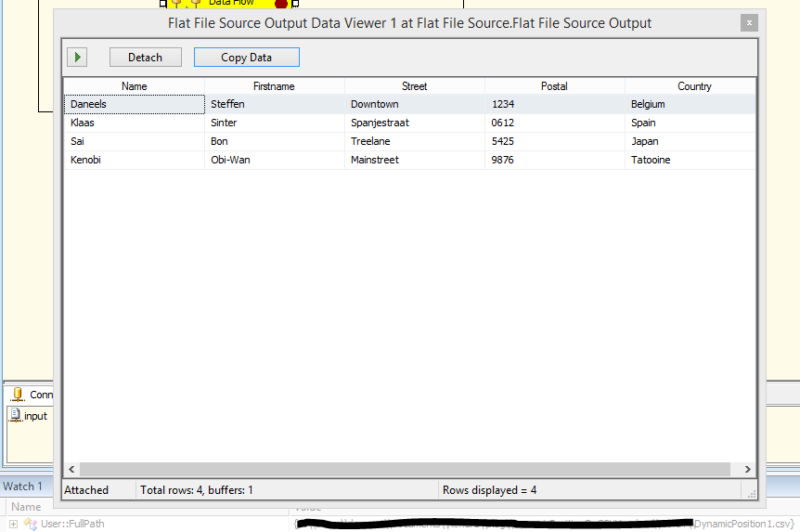
Figure 4: Output File 1
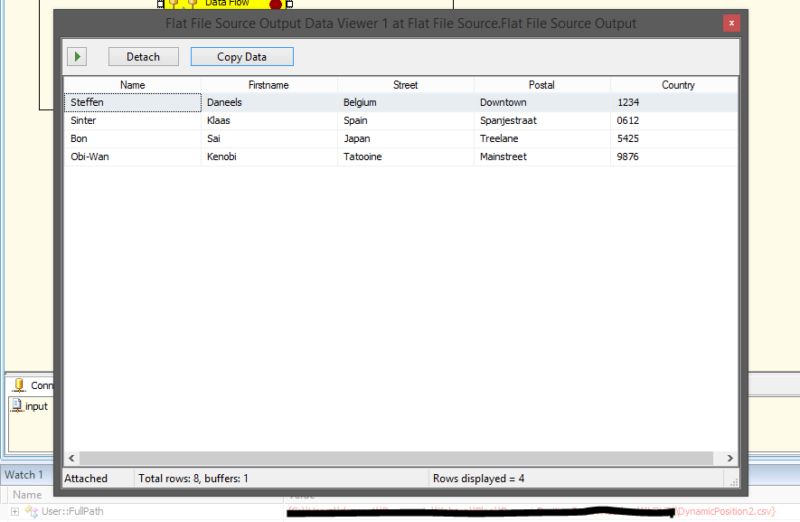
Figure 5: Output File 2
As you can see above, BIDS ignores the header names and uses the actual position of the data. So everything that is in the first position is placed in the first available column, “Name”, in this example. When you use a flat file connection the position of the data columns is quite strict. So every time the input changes, the developer has to go into the code and change the positioning within the Connection Manager. Not only that, but also the developer has to refresh the metadata in the “flat file source component(s)” those are targeting the changed connection.
Some searching on the internet only provided info to use a script. So that is what we’re going to do.
using System;
using System.Data;
using Microsoft.SqlServer.Dts.Pipeline.Wrapper;
using Microsoft.SqlServer.Dts.Runtime.Wrapper;
using Microsoft.SqlServer.Dts;
using System.Collections.Generic;
using System.IO;
using System.Windows.Forms;
[Microsoft.SqlServer.Dts.Pipeline.SSISScriptComponentEntryPointAttribute]
public class ScriptMain : UserComponent
{
string _InputFile = string.Empty;
char _delimiter = ';';
public override void PreExecute()
{
base.PreExecute();
_InputFile = this.Variables.FullPath;
}
public override void PostExecute()
{
base.PostExecute();
}
public override void CreateNewOutputRows()
{
Dictionary<string, int> columns = null;
var path = _InputFile;
var counter = 0;
using (StreamReader sr = new StreamReader(path, System.Text.Encoding.UTF8, true))
{
while (sr.Peek() >= 0)
{
var line = sr.ReadLine();
if (counter == 0)
{
// header
//trim line when encoding is wo - Bom
columns = ParseHeader(line.Trim(new char[] { '\uFEFF', '\u200B' }), _delimiter);
}
else
{
var listOfDataValues = line.Split(_delimiter);
Output0Buffer.AddRow();
Output0Buffer.Name = listOfDataValues[columns["Name"]];
Output0Buffer.Firstname = listOfDataValues[columns["Firstname"]];
Output0Buffer.Street = listOfDataValues[columns["Street"]];
Output0Buffer.Postal = listOfDataValues[columns["Postal"]];
Output0Buffer.Country = listOfDataValues[columns["Country"]];
}
counter++;
}
sr.Close();
}
}
public static Dictionary<string, int> ParseHeader(string headerRow, char delimiter)
{
var listOfColumnNames = headerRow.Split(delimiter);
var columns = new Dictionary<string, int>();
int counter = 0;
foreach (var col in listOfColumnNames)
{
columns.Add(col, counter);
counter++;
}
return columns;
}
}
The first thing that we need is to read the header row, which is on the first row. Then we to build a dictionary from this.
while (sr.Peek() >= 0)
{
var line = sr.ReadLine();
if (counter == 0)
{
// header
//trim line when encoding is wo - Bom
columns = ParseHeader(line.Trim(new char[] { '\uFEFF', '\u200B' }), _delimiter);
}
}
public static Dictionary<string, int> ParseHeader(string headerRow, char delimiter)
{
var listOfColumnNames = headerRow.Split(delimiter);
var columns = new Dictionary<string, int>();
int counter = 0;
foreach (var col in listOfColumnNames)
{
columns.Add(col, counter);
counter++;
}
return columns;
}
There is one special part in the script: line.
Trim(new char[] { '\uFEFF', '\u200B' }.
This piece of code is when the encoding of the script is in ‘UTF wo Bom’. This encoding places a special character in the first position which would make the dictionary useless.
var listOfDataValues = line.Split(_delimiter);
Output0Buffer.AddRow();
Output0Buffer.Name = listOfDataValues[columns["Name"]];
Output0Buffer.Firstname = listOfDataValues[columns["Firstname"]];
Output0Buffer.Street = listOfDataValues[columns["Street"]];
Output0Buffer.Postal = listOfDataValues[columns["Postal"]];
Output0Buffer.Country = listOfDataValues[columns["Country"]];
Based on the dictionary, build in the previous step. This way the output can be mapped to the corresponding position where the correct data is located. The downside of using this approach is that the header names need to be strictly the same as what is loaded into the dictionary. Also the amount of columns in output needs to be declared in the ‘script component‘.
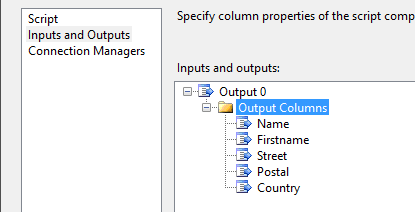
Figure 6: Output in script component
This is the result we get when using the script provided.
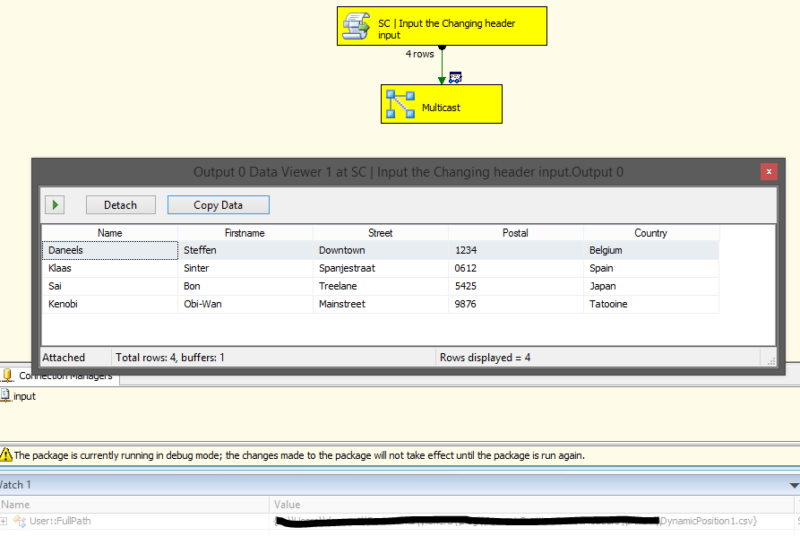
Figure 7: Output Script File 1

Figure 8: Output Script File 2
I’ve done some testing on SSDT 2010 and 2012, in both environments the issue with the column headers occurs. In this we can conclude that the script component with above code is still a valid solution on the newer versions of the Microsoft BI developer tools.

Crafted by ![]()
Crafted by ![]()





