



A SQL Server is as fast as you tune your workload. One of the things I try to do is tune the workload, a.k.a. the queries executing on my SQL Server, in order to get a better performing server. I start by looking at queries that do too many reads to retrieve a small result set. A possible obstacle, however, when working with vendor applications, is that you might not be able to tune the applications queries. This definitely limits your options, but there are still a lot of thing you can do to optimize your workload. Today we will do some testing with a giant read query and tune it in different ways by using real life scenarios.
First of all, we are going to create a database with two tables in it. We will be executing the scripts on SQL Server 2016, so some syntax might have to be changed when working with lower versions.
DROP
DATABASE
IF
EXISTS BigRead
GO
CREATE
DATABASE BigRead
GO
USE BigRead
GO
CREATE
TABLE dbo.BigReadTable_1
(
BID int
identity (-2147483648 ,1),
TheDate datetime,
TheCategory varchar(20),
TheLink int
)
GO
CREATE
TABLE dbo.BigReadTable_2
(
BID_2 int
identity(-2147483648,1),
TheDate datetime,
TheCategory varchar(20),
TheValue decimal(18,0)
)
GO
Once we have these tables, we insert some data into it.
— INSERT 1000 ROWS
SET
NOCOUNT
ON
insert
into dbo.BigReadTable_2
select
DATEADD(day,ABS(Checksum(NewID())
% 10),getdate()),
‘Category ‘+cast(ABS(Checksum(NewID())
% 10)
as
varchar),
cast((rand()*100000)
as
decimal(18,0))
GO 1000
insert
into dbo.BigReadTable_1
select
DATEADD(day,ABS(Checksum(NewID())
% 10),getdate()),‘Category ‘+cast(ABS(Checksum(NewID())
% 10)
as
varchar),(select
top 1 BID_2 from dbo.BigReadTable_2 order
by
newid())
GO 1000
insert
into dbo.BigReadTable_1
select TheDate,TheCategory,TheLink from dbo.BigReadTable_1
GO 9
insert
into dbo.BigReadTable_2
select [TheDate],[TheCategory],[TheValue] FROM dbo.BigReadTable_2
GO 9
After inserting the rows, we add a clustered index for each table.
CREATE
CLUSTERED
INDEX CI_1 ON dbo.BIGREADTABLE_2
(
BID_2
)
GO
CREATE
CLUSTERED
INDEX CI_2 ON dbo.BIGREADTABLE_1
(
TheLink
)
Now we are all set up to start our testing. The query we are going to use is the following:
select
*
from dbo.BigReadTable_2 C
inner
join
(
select
AVG(TheValue) Average,TheCategory from dbo.BigReadTable_2
group
by TheCategory
)B on C.TheCategory = B.TheCategory
inner
join
(
select
SUM(TheValue) Summer, TheCategory from dbo.BigReadTable_2
GROUP
BY TheCategory
)A on A.TheCategory = B.TheCategory
inner
join
(select
CAST(AVG(CAST(TheDate AS
FLOAT))
AS
DATETIME) AVGDate,TheLink
FROM dbo.BigReadTable_1
Group
By TheLink) D
on D.TheLink = C.BID_2
OPTION(RECOMPILE)
This is the plan we get with this query at this moment.
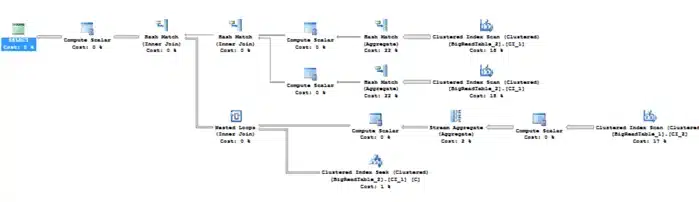
And these are the client statistics:
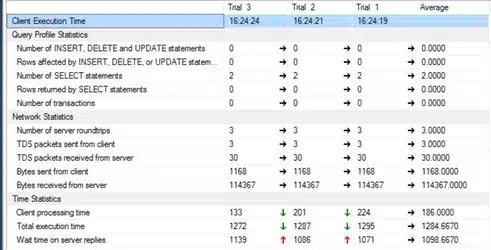
Now, what are the different possible levels of tuning for this query?
As we can see, this query is not the most optimal in filtering out data. In this case, our tuning might be quite simple. If you can discuss with your business users that you only return the fields they use, you will already see a performance increase. Let’s say, for this example, we only need the data from the BigReadTable_2.
—LEAVE OUT SOME FIELDS
select B.*,A.*,D.*,C.TheCategory from dbo.BigReadTable_2 C
inner
join
(
select
AVG(TheValue) Average,TheCategory from dbo.BigReadTable_2
group
by TheCategory
)B on C.TheCategory = B.TheCategory
inner
join
(
select
SUM(TheValue) Summer, TheCategory from dbo.BigReadTable_2
GROUP
BY TheCategory
)A on A.TheCategory = B.TheCategory
inner
join
(select
CAST(AVG(CAST(TheDate AS
FLOAT))
AS
DATETIME) AVGDate,TheLink
FROM dbo.BigReadTable_1
Group
By TheLink) D
on D.TheLink = C.BID_2
OPTION(RECOMPILE)
Here are the result for the client statistics (the plan will stay the same):
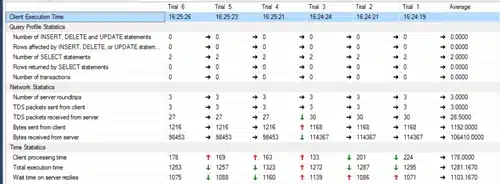
We see that we have reduced the used resources when selecting all columns. Without adding additional indexes or filtering data ,we have tuned the amount of bytes received by 25%. This shows you how important it is to just select the fields you need instead of selecting everything. There are many different ways of altering the code, but we will not cover all of them.
Now things are getting a little trickier. You no longer have control over your query. Good news, though, we can still add indexes. In SQL Server 2016, I’m using a new cool trick which can be used even in the express edition. The trick is adding an empty non-clustered columnstore index to the table, to benefit from batch mode. For more information check out Niko’s blog or check this post which explains the trick more thoroughly. So, let’s add two non-clustered columnstores.
— No Possible Index NO Code edit
DROP
INDEX
IF
EXISTS NCCI_PERF ON dbo.BigReadTable_2
GO
CREATE
NONCLUSTERED
COLUMNSTORE
INDEX NCCI_PERF ON d bo.BigReadTable_2
(
BID_2, TheDate, TheCategory, TheValue
)
WHERE BID_2 =
–1 and BID_2 =
–2
GO
DROP
INDEX
IF
EXISTS NCCI_PERF2 ON dbo.BigReadTable_1
GO
CREATE
NONCLUSTERED
COLUMNSTORE
INDEX NCCI_PERF2 ON dbo.BigReadTable_1
(
BID, TheDate, TheCategory, TheLink
)
WHERE BID =
–1 and BID =
–2
GO
Here is what we get as a result for our client statistics:

We get the same plan, but we are using batch mode. This means we are processing 1000 rows at a time instead of 1 row at a time.
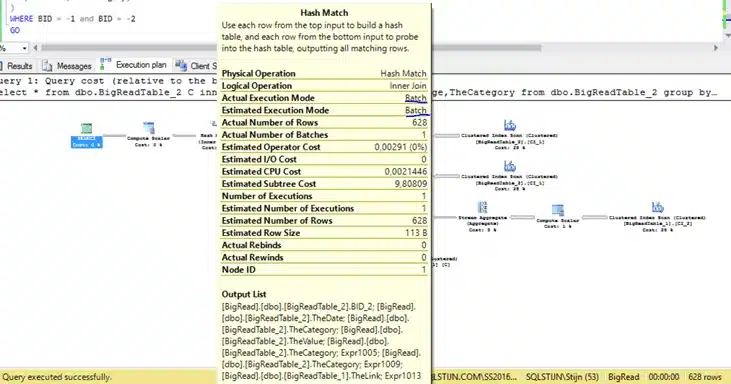
By adding these 2 empty indexes, we are reducing our execution time by 50%! Great result, I feel, for adding something empty!
This is just annoying. Almost all tools have been taken from you, but you can still tune the query! In most cases, these queries would require the highest performance of your server. So, by altering your cost threshold for parallelism, you might just force those queries to go into parallel execution, speeding them up. Let’s check the cost of the plan:
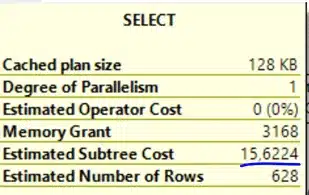
The plan has a cost of 15, so let’s lower the value for my cost threshold for parallelism to 14 (current value = 50) and see which results we get.
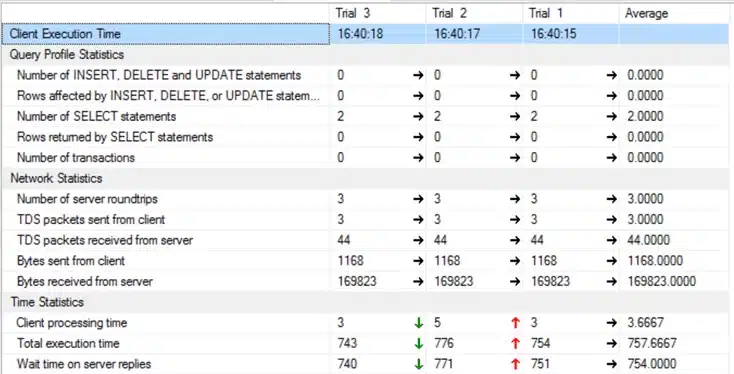
As you can see, we lowered the total execution time of our query by 30-40%, just by altering a server setting! If we look at the plan, you can see that this specific query benefits from the parallel execution. This, howeve,r can also have some downsides.

When dealing with big read queries, you have got a few tricks up your sleeve when working with SQL Server. In most cases, you have three different scenario’s:
1. You can change the code
2. You can’t change the code but can add indexes
3. You can’t change the code and can’t add indexes
For the first scenario, things are easy, since you have multiple ways of tuning your query, only one of which was shown here. For the second scenario, things get more complicated. You might be able to add an index to gain a seek, but a golden bullet for big reads does not exist. The COLUMNSTORE trick does help in most cases, but you will have to evaluate this for yourself. Then, in the last scenario, things are the trickiest. You can alter your server settings, but this might come at a price. In the example given today, the parallel plan was beneficial for this query, but it might slow down other processes or even overload your processor slowing everything down.
Thank you for reading & stay tuned!

Crafted by ![]()
Crafted by ![]()





