



When auditing SQL Server databases, one of the more common problems I see is that people add too many indexes to their tables. This has a significant performance impact on your SQL Server. First off, data inserts become slower for every update/delete/insert, because we have to maintain all indexes added for that specific table. Too many indexes also have an impact on your read performance. We all know SQL Server is pretty fast when it comes to reading data out of memory, but with a large amounts of indexes, corresponding data also needs to be stored inside your memory. This is what increases the amount of memory requiered to have the full table in memory.
If data has to be fetched from a disk, we also see a performance impact. While indexes are created to increase read performance, it may be badly influenced when adding indexes if the system is in memory pressure. To show you what the actual effects of having too many indexes are on your table, I created a few tests.
I created a script that inserts 100.000 rows into a table.
CREATE TABLE IndexMania
(
IndexManiaID int identity (1,1),
IndexColumn1 datetime,
IndexColumn2 char(1000),
IndexColumn3 char(500),
IndexColumn4 decimal (18,2),
IndexColumn5 int
)
You can see that I added a char (1000) and char (500) field to make sure I got a good amount of data to be inserted. If my data inserts are too small, SQL Server will make use of the lazy writer and not show any writes with the insert statement. By increasing the size of one row and importing 100.000 rows I bypass this issue. I am also clearing the SQL Server memory before every statement.
The indexes I created are the following
-- CLUSTERED INDEX ON ID
CREATE UNIQUE CLUSTERED INDEX [CI_IndexMania1] ON [dbo].[IndexMania]
(
[IndexManiaID] ASC
)
--- CREATE COVERING DATE INDEX
CREATE NONCLUSTERED INDEX [NCI_1] ON [dbo].[IndexMania]
(
[IndexColumn1] ASC
)
INCLUDE ( [IndexManiaID],
[IndexColumn2],
[IndexColumn3],
[IndexColumn4],
[IndexColumn5])
GO
-- 2 Additional NCI
CREATE NONCLUSTERED INDEX [NCI_2] ON [dbo].[IndexMania]
(
[IndexColumn2] ASC,
[IndexColumn3] ASC
)
INCLUDE ( [IndexManiaID],
[IndexColumn1],
[IndexColumn4],
[IndexColumn5])
CREATE NONCLUSTERED INDEX [NCI_3] ON [dbo].[IndexMania]
(
[IndexColumn4] ASC,
[IndexColumn3] ASC
)
INCLUDE ( [IndexManiaID],
[IndexColumn1],
[IndexColumn2],
[IndexColumn5])
Amount of writes (about the same for delete, insert and update)

INSERT
SQL Server Execution Times:
CPU time = 688 ms, elapsed time = 1299 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 19 ms.
UPDATE
SQL Server Execution Times:
CPU time = 407 ms, elapsed time = 623 ms.
SQL Server parse and compile time:
CPU time = 15 ms, elapsed time = 20 ms.
DELETE
SQL Server Execution Times:
CPU time = 468 ms, elapsed time = 1129 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
Amount of writes (about the same for Delete insert and update)

INSERT
SQL Server Execution Times:
CPU time = 1171 ms, elapsed time = 2745 ms.
SQL Server parse and compile time:
CPU time = 16 ms, elapsed time = 25 ms.
UPDATE
SQL Server Execution Times:
CPU time = 297 ms, elapsed time = 550 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 20 ms.
DELETE
SQL Server Execution Times:
CPU time = 734 ms, elapsed time = 3201 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
Amount of writes (about the same for Delete insert and update)
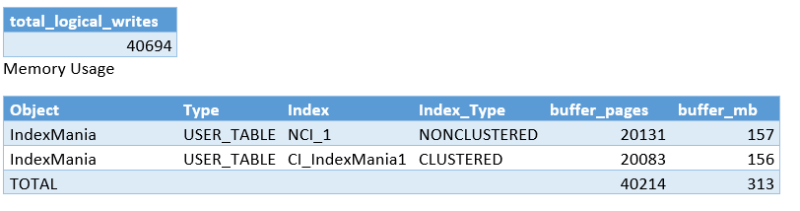
INSERT
SQL Server Execution Times:
CPU time = 1953 ms, elapsed time = 4575 ms.
SQL Server parse and compile time:
CPU time = 16 ms, elapsed time = 32 ms.
UPDATE
SQL Server Execution Times:
CPU time = 2375 ms, elapsed time = 5780 ms.
SQL Server parse and compile time:
CPU time = 16 ms, elapsed time = 23 ms.
DELETE
SQL Server Execution Times:
CPU time = 1718 ms, elapsed time = 7761 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
Amount of writes
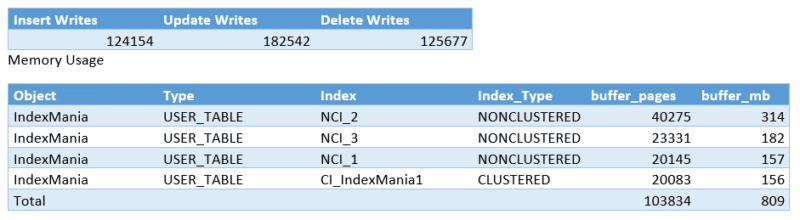
INSERT
SQL Server Execution Times:
CPU time = 42468 ms, elapsed time = 47094 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 21 ms.
UPDATE
SQL Server Execution Times:
CPU time = 108063 ms, elapsed time = 125766 ms.
SQL Server parse and compile time:
CPU time = 10 ms, elapsed time = 10 ms.
DELETE
SQL Server Execution Times:
CPU time = 54922 ms, elapsed time = 73162 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
As seen in our test, we can conclude that each added index has an impact on our write performance and on the amount of data stored in memory to facilitate the index.
When inserting data to a heap table, we needed about 20020 writes to insert 100.000 records. There was almost no difference with the amount of writes while writing to a clustered index. When adding a covering index, the amount of writes doubled. This is normal because we will keep the data two times. When adding another two covering indexes, we are doing about 4 times the original amount of writes. There are some discrepancies in the amount of writes, but this is due to the fact that to execute some of the queries we needed to spill to TEMPDB. This gave a larger amount of writes than the amount of indexes increased. After multiple tests we can see that we will need 4 times the amount of writes purely for the indexes. (DELETE, UPDATE and INSERT)
When inserting data, we have seen that while inserting into a heap table we have an average of about 1 second, when adding a clustered index this increased to an average of 2-3 seconds. When adding 1 covering index this increased to 4-6 seconds, and with two additional covering indexes the amount of time exploded to a whopping 45 – 50 seconds to insert the same workload.
After inserting 100.000 rows into the heap table, we have seen that we use 156MB of the memory to facilitate this table. When adding the clustered index, this amount stays exactly the same. When adding 1 covering index, this doubled, which means we are now keeping 2 copies of the data inside the memory. When adding the 2 additional covering indexes, we see that we are keeping the same data 4 times inside our memory.
We should careful when adding additional indexes. This does not only have an impact on our insert/update/delete performance, but this also impacts the amount of memory used for that specific table. We want to be able to get all items out of our cache, which will be in nanoseconds instead of milliseconds when retrieving data from disk. So we have to keep in mind that every index that we add might take additional space inside your cache, removing other objects out of your cache and slowing them down.
In the example of today we were using covering indexes which is actually saying double my data. Keep in mind however that this is not a pledge to stop using indexes even covering indexes. Indexes will help your performance incredibly if used in the correct way. As a general recommendation I would say try to keep your indexes as small as possible and only include the fields you need to reduce the overhead of your index.
Thank you for reading and stay tuned!

Crafted by ![]()
Crafted by ![]()





