



In SQL Server 2016 heeft Microsoft ons voorzien van tal van nieuwigheden. Naast de talrijke mooie wijzigingen in de SQL Server engine, SSAS en SSRS, is er ook aandacht besteed aan SSIS 2016. Deze verbeteringen staan wat minder in de kijker, maar zijn daarom niet minder de moeite waard.
Als ervaren SSIS-ontwikkelaar word ik zeer blij van de native ondersteuning voor OData4. Die biedt ons namelijk de mogelijkheid om SSIS aan te sluiten op een OData-bron, en OData4-berichten rechtstreeks op te pikken. Daarnaast biedt SQL Server 2016 nu ook de mogelijkheid om de JSON-inhoud om te zetten naar relationele data, zodat u ze verder kan verwerken in uw OLTP of DWH. Output van relationele data naar JSON is uiteraard ook mogelijk. Maar voor ik u verder rond de oren sla met technische termen, volgt eerst even een korte uitleg over OData4 en JSON.
OData staat voor Open Data Protocol. Het is een communicatieprotocol dat in 2007 initieel werd opgestart door Microsoft, maar inmiddels een internationale standaard is geworden. OData-pakketten zorgen dat computersystemen onderling communiceren. Ze aanwezig op het internet of uw interne netwerk, en connecteren bijvoorbeeld ook tussen uw browser en een webserver. Een voorbeeld: u wil een midweekje Tenerife boeken bij uw favoriete reisoperator. Uw browser stuurt een OData-pakket naar de webserver van de reisorganisatie om te informeren naar prijs en beschikbaarheid. De webserver antwoordt vervolgens met een OData-pakket dat de prijzen van uw selectie bevat.
JSON staat voor Javascript Object Notation en is een gestandaardiseerd gegevensformaat dat data-objecten gebruikt als tekst, die bestaan uit een of meerdere attributen met bijhorende waarde. Als u zich OData inbeeldt als een vrachtwagen, dan dient u JSON te zien als de lading tomaten.
Een voorbeeld:
{
"@odata.context": "http://services.odata.org/V4/OData/OData.svc/$metadata#Products",
"value": [
{
"ID": 0,
"Name": "Meat",
"Description": "Red Meat",
"ReleaseDate": "1992-01-01T00:00:00Z",
"DiscontinuedDate": null,
"Rating": 14,
"Price": 2.5
},
{
"ID": 1,
"Name": "Milk",
"Description": "Low fat milk",
"ReleaseDate": "1995-10-01T00:00:00Z",
"DiscontinuedDate": null,
"Rating": 3,
"Price": 3.5
}
]
}
U hebt in bovenstaand voorbeeld waarschijnlijk twee records gezien in een formaat dat vergelijkbaar is met xml. Als we nu spreken over DataWareHousing, is deze OData4-integratie dan niet vooral een duurdere en hippere vervanging van onze oude getrouwe csv-files waarmee we al decennialang de loads verzorgen? Ik geloof dat er wel degelijk voordelen zijn die het de moeite waard maken om deze aanpak te overwegen, dit zijn de voornaamste redenen.
U zal nu waarschijnlijk opmerken dat dit allemaal ook al mogelijk was in eerder versies van SQL Server, en u heeft gelijk. Het belangrijke verschil is dat u toen gebruik moest maken van custom extensies in SSIS (die u kon downloaden van de MS website). Bovendien werd Odata4 niet ondersteund door SQL Server. Vandaag zijn alle benodigde componenten native aanwezig in SSIS. Hoe makkelijk dit allemaal gaat, ziet u hier:
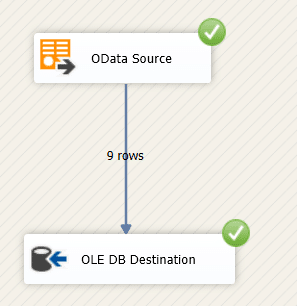
Onze bron is de Northwind Odata webservice, en onze destination table is een SQL Server 2016 tabel. Het opzetten gaat vlot, en doet u zo:
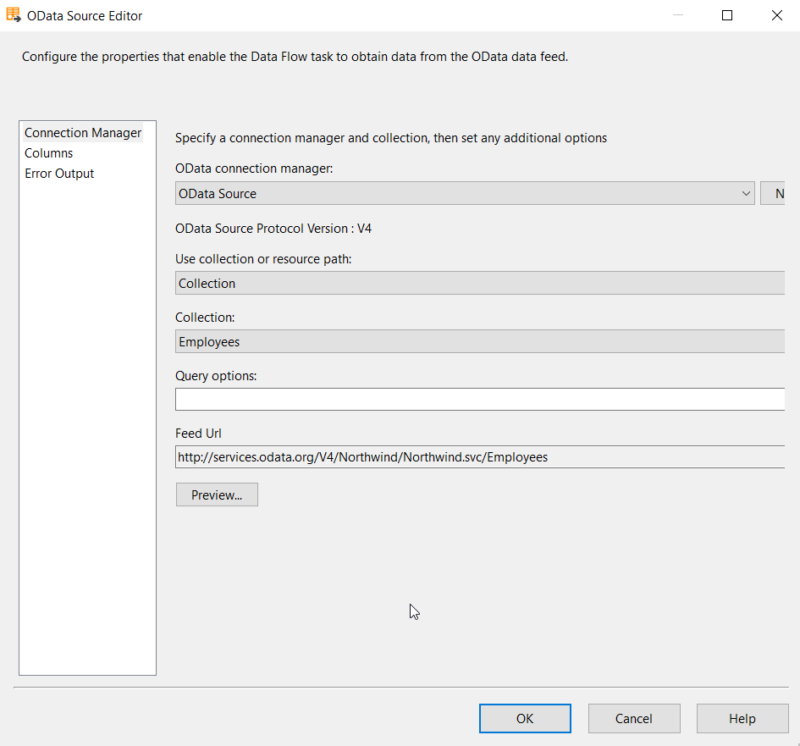
In de Query options kunt u al een eerste keer filteren op de bron zelf. Dit beperkt de downloadgrootte naar de server. U kunt bijvoorbeeld kiezen om enkel Empoyees te selecteren uit Londen, of updates/ inserts vanaf een bepaalde datum (de laatste load date). Voor het voorbeeld uit Londen gebruiken we de volgende filter: $filter=City eq ‘London’. U kunt ook werken met contains, dat is geen probleem.

Bij de Columns sectie kunt alle kolommen afvinken die u niet nodig heeft. SSIS zal de columns wel nog steeds downloaden, en pas in de component beslist om ze niet verder door te sturen in de pipeline.
Kunt u dan niet rechtstreeks op de bron besluiten om slechts bepaalde kolommen te downloaden? Natuurlijk kan dat. Hiervoor werkt u met het select statement bij de Query Options. In ons geval: $select=EmployeeID, LastName, FirstName, Title, HireDate, Address,City. Maar nu zijn we natuurlijk onze filter kwijt. Met een & kunt u query options aan elkaar koppelen. Bijvoorbeeld: $select=EmployeeID, LastName, FirstName, Title, HireDate, Address, City & $filter=City eq ‘London’.
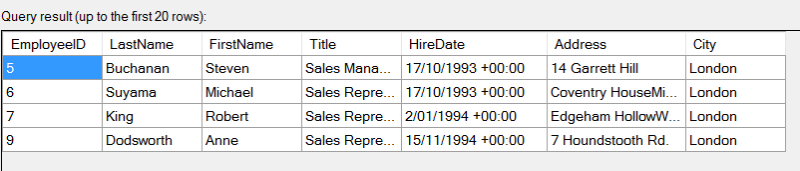
Een order by is steeds een blocking point in onze ETL, dus het zou leuk zijn mochten we al kunnen sorteren op de bron zelf. Dat kan met Odata. Via de query options gebruikt u het $orderby statement.
Dit is ons finale Query Option Statement:
$select=EmployeeID, LastName, FirstName, Title, HireDate, Address, City & $filter=City eq 'London' & $orderby=HireDate desc

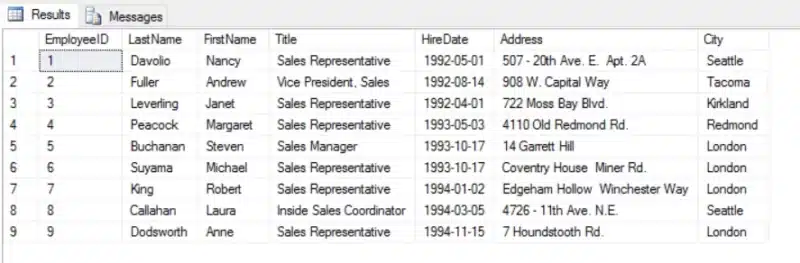
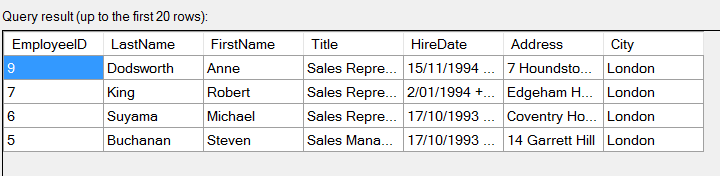
Hieronder ziet u het resultaat van onze preview. We downloadden van onze Odata-bron een beperkt aantal kolommen: enkel met de medewerkers die in Londen wonen, en sorteren aflopend op HireDate. Probeer dat eens met csv-bestand.
Nu dienen we enkel nog te verbinden naar een SQL tabel, en de data stroomt netjes binnen in onze database.
Als afsluiter kunnen we stellen dat Odata een snel, veilig en makkelijk te integreren communicatieprotocol is, en perfect te combineren valt met SSDT en zelfs PowerBI. Odata gaat echter veel breder dan het Microsoft-ecosysteem alleen. Andere grote technologiespelers zoals IBM, Oracle en SAP, maar ook platforms zoals SalesForce en Hadoop bouwden een native integratie van Odata in hun software. Odata is algemeen aanvaard in de data community, en zal nog lange tijd bij ons blijven als open standaard voor communicatie tussen systemen onderling.

Crafted by ![]()
Crafted by ![]()





