



SQL Server 2017 and Azure SQL Database introduced a whole new set of query improvements regarding performance. These modifications are all part of the so called “adaptive query processing feature family”, which includes three major changes: batch mode adaptive joins, batch mode memory grant feedback and interleaved execution for multi-statement table valued functions. In this article, I will focus on the, in my humble opinion, most fascinating one: batch mode adaptive joins.
Every DBA who has ever been given the task to tune a database or monitor its performance knows the phenomenon, your ‘oh so blazingly fast query’ suddenly runs slow… One of the most common causes for this issue is parameter sniffing. When you execute a parameterized query for the first time, SQL Server computes a set of execution plans based on the provided parameters and picks the plan with the lowest estimated cost. SQL Server caches the chosen plan and reuses it for future executions. The problem arises when the values in the table aren’t evenly distributed. In the case of ad-hoc queries, SQL Server is able to generates different execution plans based on these provided values. When using parameterized queries on the other hand, a one-size-fits-it-all plan is created based on the provided values of the first execution.
To show you the impact, we’ll execute the same query twice using different parameters. To make the data unevenly distributed I added some records to the [Sales].[InvoiceLines] table. It now has 67000 records for StockItemID 1 and 20 records for StockItemID 227. In all the following examples we’ll use the WorldWideImporters database which is available on GitHub.
Let’s kick off with a short demonstration on how parameter sniffing can influence your performance. We’ll first create a very basic stored procedure:
CREATE PROCEDURE [dbo].[GetCustomersByStockItemID]
@StockItemID int
AS
BEGIN
SET NOCOUNT ON;
SELECT DISTINCT(i.CustomerID)
FROM [Sales].[InvoiceLines] il
inner join [Sales].[Invoices] i on il.InvoiceID = i.InvoiceID
WHERE il.StockItemID = @StockItemID
END
GO
Now we’ll execute this stored procedure for StockItemID 227.
SET STATISTICS IO, XML, TIME ON
GO
EXEC dbo.GetCustomersByStockItemID @StockItemID = 227
GO
As you can see SQL Server uses 2 nonclustered index seeks and 60 logical reads on the [Sales].[Invoices] table to execute the procedure.
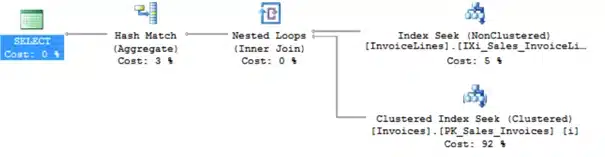

Next, let’s execute the same stored procedure but now for StockItemID 1 instead of 227.
SET STATISTICS IO, XML, TIME ON
GO
EXEC dbo.GetCustomersByStockItemID @StockItemID = 1
GO
SQL Server cached the previously generated execution plan and, as you can see, chooses to reuse the plan. Because there are a lot more records in Sales.InvoiceLines holding StockItemID 1, we now have over 200k logical reads on [Sales].[Invoices]!
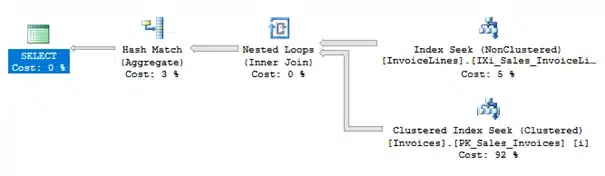

To check if SQL Server would create a different execution plan for StockItemID 1, we must first clear the procedure cache and then execute the stored procedure again.
DBCC FREEPROCCACHE()
GO
SET STATISTICS IO, XML, TIME ON
GO
EXEC dbo.GetCustomersByStockItemID @StockItemID = 1
GO
In this case SQL Server chooses to scan the nonclustered index on [Sales].[Invoices] and the number of logical reads drops to 166.
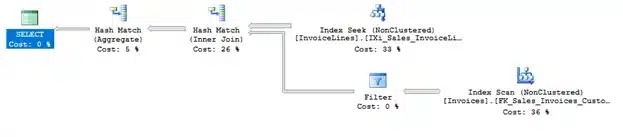

Prior to SQL Server 2017 one possible solution would be to add ‘OPTION (RECOMPILE)’ at the end of your stored procedure. This way SQL Server compiles a single-use plan for each execution, based on the provided values. Although this is a viable solution, it has its downsides, especially for large and complicated queries with high compilation times. Starting from SQL Server 2017 we have a new tool in the shed: batch mode adaptive joins. This new type of join enables SQL Server to postpone the choice between a hash and nested loop join until the first input has been processed, in our case the seek on Sales.InvoiceLines. The join operator holds a threshold. If the input exceeds this threshold, SQL continues to use a hash join. If the input falls below the threshold, SQL Server switches to a nested loop join.
To be able to use adaptive joins, the database must be in compatibility mode 140 and SQL Server must be able to use batch mode processing. To enable batch mode processing, I used a little trick Itzik Ben-Gan wrote about. Basically, you create a filtered nonclustered columnstore index that can’t have any rows in it.
CREATE NONCLUSTERED COLUMNSTORE INDEX [NCCI_Sales_Invoices_InvoideId] ON [Sales].[Invoices]
(
[InvoiceID]
)where invoiceId = 1 and invoiceId = -1
WITH (DROP_EXISTING = OFF, COMPRESSION_DELAY = 0)
If we execute the stored procedure again, SQL Server should be able to switch between joins. First execute the proc using StockItemID 227:
SET STATISTICS IO, XML, TIME ON
GO
EXEC dbo.GetCustomersByStockItemID @StockItemID = 227
GO
If you hover the adaptive join operator you can see that the number of rows falls below the predefined threshold of 436 rows. Therefore, SQL Server switches to a nested loop join and seeks the nonclustered index on [Sales].[Invoices] using 60 logical reads.
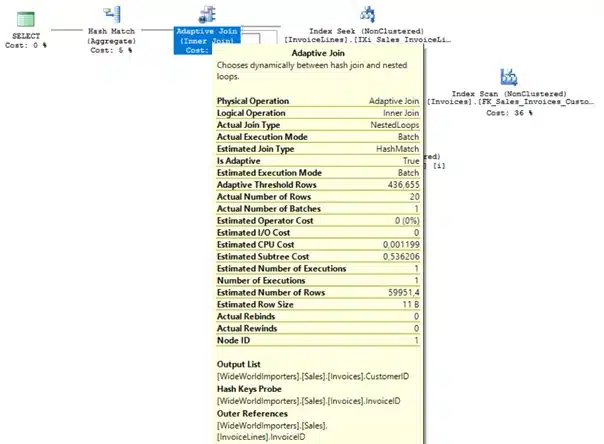

Now let’s execute the same procedure again for StockItemID 1.
SET STATISTICS IO, XML, TIME ON
GO
EXEC dbo.GetCustomersByStockItemID @StockItemID = 1
GO
SQL Server reuses the execution plan, as you can see the number of rows exceeds the predefined threshold. Consequently, SQL Server continues to use a hash join and scans the nonclustered index on [Sales].[Invoices] using only 166 logical reads!
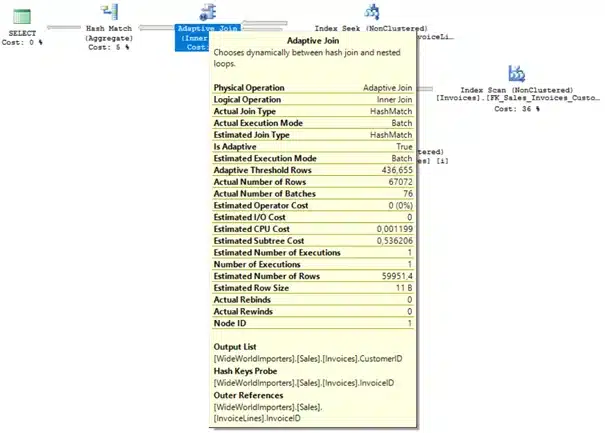

An important disadvantage of adaptive joins is that SQL Server will grant a higher amount of memory compared to when using a regular nested loop join. This is because the optimizer grants memory as if it was executing a hash join. If you are on a system with an already limited amount of memory caution should be paid, especially regarding queries that are executed a lot. As a second downside, Microsoft states there’s an overhead for the build phase as it is a stop-and-go operation. Although I couldn’t witness any significant difference, this overhead might be more noticeable in large environments.
If any of the previously described disadvantages is a blocking factor for you, you can always choose to disable adaptive joins. They can be disabled at either database or statement scope. To disable the feature for all queries executed on a specific database, use:
ALTER DATABASE SCOPED CONFIGURATION SET DISABLE_BATCH_MODE_ADAPTIVE_JOINS = ON;
As a last option you can choose to use trace flag 9398 as well, this can be set on global, session and query level.
If you wish to disable the feature specifically for one query, you can add following hint at the end of the query:
OPTION(USE HINT('DISABLE_BATCH_MODE_ADAPTIVE_JOINS'));
As a last option you can choose to use trace flag 9398 as well, this can be set on global, session and query level.
With the introduction of adaptive joins, we have a new nifty tool to improve and maintain query performance on our beloved database platform. Even though it comes with an additional cost, you will get improved flexibility in return, especially for unevenly divided data.

Crafted by ![]()
Crafted by ![]()





