



Support wise it is backed up by a team of support staff who will monitor its health, and more importantly debug tickets can be filed via your regular Azure support interface. This allows Databricks users to focus on developing rather than having to stress over infrastructure management.
Ok so now you’ve decided to work with Databricks, but how to get started? What are the steps that you will have to go through? What are the considerations that you will have to take. It first sight it looks complicated but if you follow this guideline we’ll have you up and running in minutes.
There are some important things to know before diving into the more advanced stuff. Azure Databricks comes with its own user management interface. In every workspace the Workspace admins can create users and groups inside that workspace, assign them certain privileges, etc.
While users in AAD are equivalent to Databricks users, by default AAD roles have no relationship with groups created inside Databricks, unless you use SCIM for provisioning users and groups. With SCIM, you can import both groups and users from AAD into Azure Databricks, and the synchronization is automatic after the initial import.
Azure Databricks also has a special group called Admins, not to be confused with AAD’s role Admin. The first user to login and initialize the workspace is the workspace owner, and they are automatically assigned to the Databricks admin group. This person can invite other users to the workspace, add them as admins, create groups, etc.
Azure Databricks deployments for smaller organizations, PoC applications, or for personal education hardly require any planning. You can spin up a Workspace using Azure Portal, name it appropriate and in a matter of minutes, you can start creating Notebooks, and start writing code.
Enterprise-grade large scale deployments, that require a more secure environment, CI/CD are a different story altogether. Some upfront planning is necessary to manage Azure Databricks deployments across large teams. In that case when you start working with Databricks, always start with planning your Hierarchy.
Of course you could apply any model that can be found on the “Azure enterprise scaffold: Prescriptive subscription governance” (https://docs.microsoft.com/en-us/azure/cloud-adoption-framework/reference/azure-scaffold#departments-and-accounts) article, but the most used model is actually the business division model. This model is also officially recommend by the Databricks team, and starts with assigning workspaces based on a related group of people working together collaboratively.
This helps in streamlining the access control matrix within your workspace (folders, notebooks etc.) across all your resources that the workspace interacts with (storage, related data stores like Azure SQL DB, Azure SQL DW etc.). This design pattern aligns well with the Azure Business Division Model chargeback model.
Customers commonly partition workspaces based on teams or departments and by doing so will arrive at a usable division naturally. But it is also important to keep the Azure Subscription and Workspace limits in mind while doing so. These limits are at this point in time and might change going forward. Some of them can also be increased if needed. For more help in understanding the impact of these limits or options of increasing them, please contact Microsoft or Databricks technical architects.
Due to these scalability reasons, it is highly recommended to separating the production and dev/test environments into separate subscriptions.
While you can deploy more than one Workspace in a VNet by keeping the associated subnet pairs separate from other workspaces, it is recommend that you should only deploy one workspace in any Vnet. Doing this aligns better with the Workspace level isolation model.
When considering putting multiple workspaces in the same Vnet to be able to share common networking resource, also know that you can achieve the same while keeping the Workspaces separate by following the hub and spoke model and using Vnet Peering to extend the private IP space of the workspace Vnet. Know that separating them also facilitates the CI/CD possibilities of the complete solution.
In larger environments you will probably want to integrate your Databricks workspace into an existing vNet. When doing so there are some guidelines that you should follow. While doing so gives you more control over the networking layout. It is important to understand this relationship for accurate capacity planning.
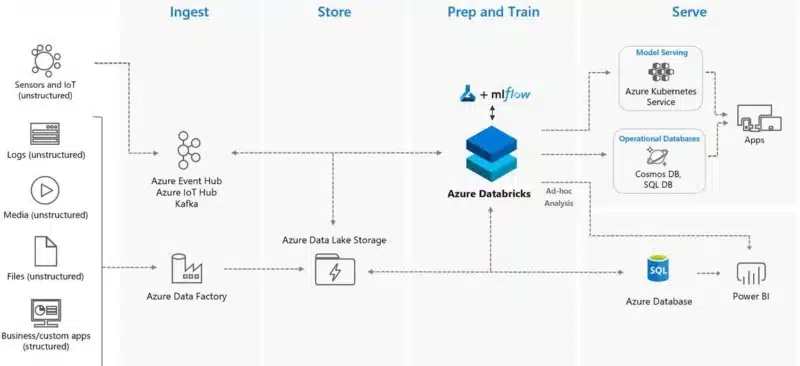
Choosing your CIDR ranges immediately impacts your cluster sizes, and thus, should always be planned beforehand. There is some extra information needed before we can calculate how many nodes one can use across all clusters for a given VNet CIDR. It will soon become clear that selection of VNet CIDR has far reaching implications in terms of maximum cluster size.
But, because of the address space allocation scheme, the size of private and public subnets is constrained by the VNet’s CIDR.
These constraints are the main reason why it’s recommend that you should only deploy one workspace in any VNET.
This rules can then easily be put into this table:
Never store Production Data in the Default DBFS Folders. There are several important reasons for this
Of course this recommendation doesn’t apply to Blob or ADLS folders explicitly mounted as DBFS by the end user.
It is a significant security risk to expose sensitive data such as access credentials openly in Notebooks or other places such as job configs, init scripts, etc. You should always use a vault to securely store and access them. Although you can either use ADB’s internal Key Vault for this purpose or use Azure’s Key Vault (AKV) service we highly recommend to use Azure’s Key Vault, create separate AKV-backed secret scopes and corresponding AKVs to store credentials pertaining to different data stores. This will help prevent users from accessing credentials that they might not have access to. Since access controls are applicable to the entire secret scope, users with access to the scope will see all secrets for the AKV associated with that scope.
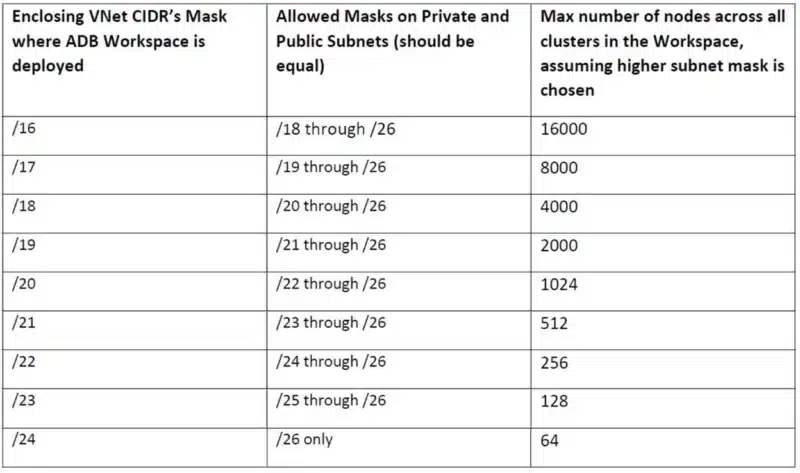
The following tables can be used as a guidelines for Selecting, Sizing, and Optimizing Clusters Performance in your workspaces. When it comes to taxonomy, Azure Databricks clusters are divided along the notions of “type”, and “mode.”
There are two types of Databricks clusters, according to how they are created. Clusters created using UI and Clusters API are called Interactive Clusters, whereas those created using the Jobs API are called Jobs Clusters.

Each cluster can be one of two modes: Standard and High Concurrency. Regardless of types or mode, all clusters in Azure Databricks can automatically scale to match the workload, using a feature known as Autoscaling.
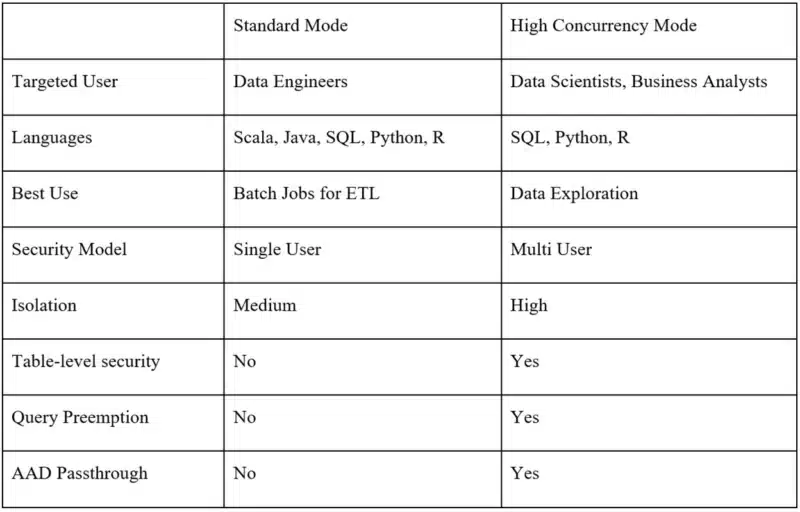
To allocate the right amount and type of cluster repressure for a job, we need to understand how different types of jobs demand different types of cluster resources.
ELT – In this case, data size and deciding how fast a job needs to be will be a leading indicator. Spark doesn’t always require data to be loaded into memory in order to execute transformations, but you’ll at the very least need to see how large the task sizes are on shuffles and compare that to the task throughput you’d like. To analyze the performance of these jobs start with basics and check if the job is by CPU, network, or local I/O, and go from there. Consider using a general purpose VM for these jobs. Once you see where the bottleneck resides, then you can switch to either Storage or Compute Optimized VM’s
Interactive / Development Workloads – The ability for a cluster to auto scale is most important for these types of jobs. In this case taking advantage of the Autoscaling feature will be your best friend in managing the cost of the infrastructure.
Machine Learning – To train machine learning models it’s usually required cache all of the data in memory. Consider using memory optimized VMs so that the cluster can take advantage of the RAM cache. You can also use storage optimized instances for very large datasets. To size the cluster, take a % of the data set → cache it → see how much memory it used → extrapolate that to the rest of the data.
Streaming – You need to make sure that the processing rate is just above the input rate at peak times of the day. Depending peak input rate times, consider compute optimized VMs for the cluster to make sure processing rate is higher than your input rate.
It is impossible to predict the correct cluster size without developing the application because Spark and Azure Databricks use numerous techniques to improve cluster utilization. In theory, Spark jobs, like jobs on other Data Intensive frameworks (Hadoop) exhibit linear scaling. For example, if it takes 5 nodes to meet SLA on a 100TB dataset, and the production data is around 1PB, then prod cluster is likely going to be around 50 nodes in size.
Develop on a medium sized cluster of 1 to 8 nodes, with VMs matched to the type of workload. After meeting functional requirements, run end to end test on larger representative data while measuring CPU, memory and I/O used by the cluster at an aggregate level.
Performing these steps will help you to arrive at a baseline cluster size which can meet SLA on a subset of data. However, there are scenarios where Spark jobs don’t scale linearly. In some cases this is due to large amounts of shuffle adding an exponential synchronization cost.
A shuffle occurs when we need to move data from one node to another in order to complete a stage. Depending on the type of transformation you are doing you may cause a shuffle to occur. This happens when all the executors require seeing all of the data in order to accurately perform the action. If the Job requires a wide transformation, you can expect the job to execute slower because all of the partitions need to be shuffled around in order to complete the job. Eg: Group by, Distinct.
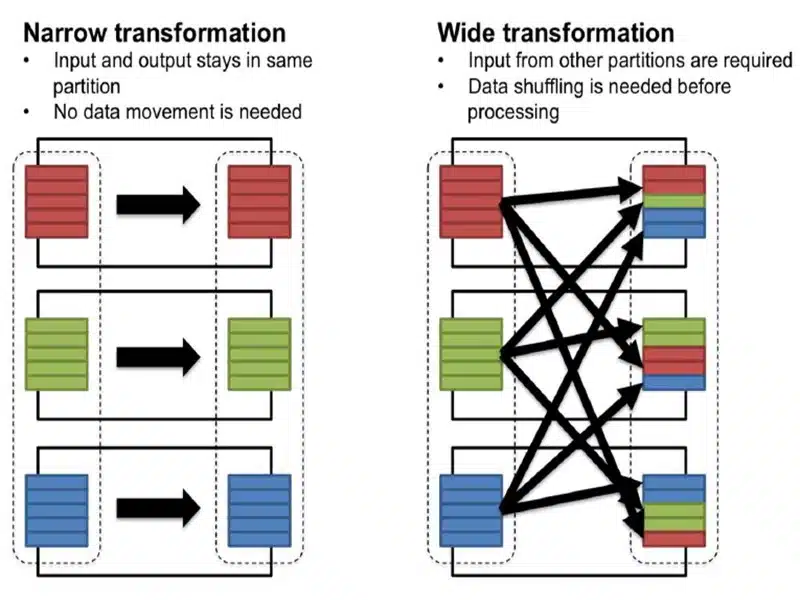
You’ve got two control knobs of a shuffle you can use to optimize
These two determine the partition size, which we recommend should be in the Megabytes to 1 Gigabyte range. If your shuffle partitions are too small, you may be unnecessarily adding more tasks to the stage. But if they are too big, you will get bottlenecked by the network. So tuning this will directly impact the usage on your cluster
Source: https://github.com/Azure/AzureDatabricksBestPractices/blob/master/toc.md

Crafted by ![]()
Crafted by ![]()





