



Data Lakes are the foundations of the new data platform, enabling companies to represent their data in an uniform and consumable way. The flexibility, agility, and security of having structured, unstructured, and historical data readily available in segregated logical zones brings now possibilities and extra transformational capabilities to businesses. It is key to understand what defines a usable Data Lake. In this document, we’ll describe how to setup a Data Lake in such a way that it will become the efficient Data Lake that users are looking for.
This will takes planning, discipline, and governance to make sure it doesn’t become a garbage bin for Data.
One of the innovations of the data lake is early ingestion and late processing, which is similar to ELT, but the T is far later in time and sometimes defined on the fly as data is read. Adopting the practice of early ingestion and late processing will allow integrated data to be available ASAP for operations, reporting, and analytics. This demands diverse ingestion methods to handle diverse data structures, interfaces, and container types; to scale to large data volumes and real-time latencies; and to simplify the onboarding of new data sources and data sets.
Within a Data Lake, it is key to define multiple zones that will allow you to define logical and/or physical separation of data. This is important because otherwise it will become very difficult to keeps the environment secure, organized, and Agile. Typically, we recommend the usage of 3 or 4 zones, but fewer or more may be leveraged. A generic 4-zone system should include the following:
This arrangement can be adapted to the size, maturity, and unique use and even extend to specific business as necessary, but will leverage physical separation via exclusive data lakes or logical separation through the deliberate structuring of directories and access privileges, or sometimes the combination of both.
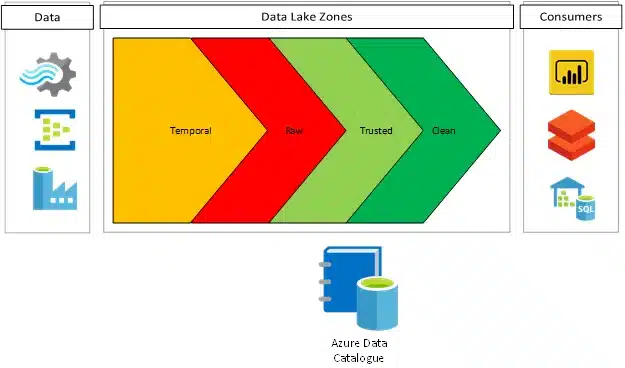
Establishing and maintaining these well-defined zones is the most important activity to create a healthy and efficient data Lake. At the same time, it is also important to understand what these zones don’t provide! A Data Lake is not a Disaster Recovery or Data Redundancy policy.
Although creating zones in a different Data lake store in another location sometimes might be considered in DR, it’s still important to think about a solid underlying architecture to ensure redundancy and resilience.
Coming from the traditional RDBMS the Data Lake offers extraordinary amount of control over exactly how to store data. Opposed to an RDBMS storage engine, Data Lakes have an array of elements such as file sizes, type of storage (row vs. columnar), degree of compression, indexing, schemas, and block sizes. These are all related to the Data Lake ecosystem of tools commonly used for accessing data in a lake.
A small file is one which is significantly smaller than the (HDFS) default block size of128 MB.
If we are storing small files, given the large data volumes of a data lake, we will end up with a very large number of files. Every file is represented as an object in the cluster’s name node’s memory, each of which occupies 150 bytes, as a rule of thumb.
So 100 million files, each using a block, would use about 30 gigabytes of memory. The takeaway here is that Hadoop ecosystem tools are not optimized for efficiently accessing small files. They are primarily designed for large files, typically an even multiple of the block size.
small files are the exception in a Data lake and processing too many small files will cause massive performance issues, Data Lakes wants large, splittable files so that its massively distributed engine can leverage data locality and parallel processing.
Knowing this it’s best to leverage fewer larger files rather than a higher quantity of smaller files. Ideally, you want a partition pattern that will result in the least amount of small files as possible. A general rule of thumb is to keep files around 1GB each, and files per table no more than around 10,000. This will vary based on the solution being developed as well as the processing type of either batch or real-time.
Because of the native support in Azure Data Factory we recommend to use the following file format types:
Gzipped Text format (CSV’s)
JSON format (For IOT purposes)
Avro format (For archiving purposes)
ORC format (Recommended Format for datasets > 1GB)
Parquet format
ORC is a mix of row and column format, that means stores collections of rows and within the rows the data is stored in columnar format. This format is splittable what means that parallel operations can be performed easily. This makes ORC is a prominent columnar file format designed for Hadoop workloads. The ability to read, decompress, and process only the values that are required for the current query is made possible by columnar file formatting. While there are multiple columnar formats available, many users have adopted ORC. There are demonstrations that ORC is significantly faster than File or Parquet storages.
Data is stored in records, does not exceed in fast querying of the data, but has a high usability and is very easy to manipulate. Commonly used in nearly every organization; easily parsed; often a good use case for bulk processing; Not always best choice for advanced analytics depending on use case.
Avro is mainly used for serialization, is a fast binary format that supports block compression and is splittable. The most important feature is that AVRO supports schema evolution which makes it extremely useful for archivation. In terms of schema evolution Avro understands add,update,delete while parquet can add at the end and ORC can’t do any of those (yet)
Parquet is a column oriented data store so when specific columns are needed performance is excellent. Parquet format sometimes becomes more computationally intensive on the write side–e.g., requiring RAM for buffering and CPU for ordering the data etc. but it should reduce I/O, storage and transfer costs as well as make for efficient reads especially with SQL-like (e.g., Hive or SparkSQL) queries that only address a portion of the columns.
As new data sources are added, and existing data sources get updated or modified, maintaining a record of the relationships within and between datasets becomes more and more important. These relationships might be as simple as the renaming of a column, or as complex as joining multiple tables from different sources, each of which might have several upstream transformations themselves.
In this context, lineage will help to provide both traceability to understand where a field or dataset originates from and an audit trail to understand where, when, and why a change was made.
This may sound simple, but capturing details about data as it moves through the Lake becomes exceedingly hard with the increase of volume and versions, even with some of the purpose-built software being deployed today.
In the context of the Data Lake, this will include documenting and versioning any batch and streaming tools that touch the data (such as MapReduce and Spark), but also any external systems that may manipulate the data, such as Azure DWH and Databricks systems. This looks like a daunting task, but even a partial lineage graph or Visio drawing can fill in the gaps of traditional systems, especially with regulations such as GDPR.
Without this control, a data lake can easily turn into a data swamp, which is a disorganized and undocumented data set that’s difficult to navigate, govern, and leverage. Key is to Establish control via policy-based data governance.
A data steward or curator should enforce a data lake’s anti-dumping policies. Even so, the policies should allow exceptions — as when a data analyst or data scientist dumps data into their temporal analytics sandboxes.
The Data Steward is also responsible to document the data as it enters the lake using metadata, an information catalog, business glossary, or other semantics so users can find data, optimize queries, govern data, and reduce data redundancy.
In a Data Lake, all data is welcome, but not all data is treated equal. Therefore, it is critical to define the source of the data and how it will be managed and consumed.
Stringent cleansing and data quality rules might need to be applied to data that requires regulatory compliance, heavy end-user consumption, or auditability. On the other hand, not much value can be gained by cleansing social media data or data coming from various IoT devices.
One can also make a case to consider applying the data quality checks on the consumption side rather than on the acquisition side. This means that often, a single Data Quality architecture might not apply for all types of data.
You always have to take into consideration that cleansing the data, could impact the results used for analytics. A field-level data quality rule that fixes values in the datasets can sway the outcomes of predictive models as those fixes can impact the outliers. Data quality rules to measure the usability of the dataset by comparing the ‘expected vs. received size of the dataset’ or ‘NULL Value Threshold’ might be more suitable in such scenarios.
Often the level of required validation is influenced by legacy restrictions or internal processes that already are in place, so it’s a good idea to evaluate your company’s existing processes before setting new rules.
A key component of a healthy Data Lake is privacy and security, including topics such as role based access control, authentication, authorization, as well as encryption of data at rest and in motion.
From a pure Data Lake and data management perspective the main topic tends to be data obfuscation including tokenization and masking of data. These two concepts should be used to help the data itself adhere to the security concept of least privilege. Restricting access to data also has legal implications for many businesses looking to comply with national and international regulations for their vertical.
Restriction access takes several forms; the most obvious is the prodigious use of zones within the storage layer. In short, permissions in the storage layer can be configured such that access to the data in its most raw format is extremely limited. As that data is later transformed through tokenization and masking (i.e. hiding Personal sensitive data) access to data in later zones can be expanded to larger groups of users.
There are two levels of Access Control within Azure Data Lake, Access ACLs and Default ACLs. The Access ACL controls the security of objects within the data lake, whereas the Default ACLs are predefined settings that a child object can inherit from upon creation.
At a high level, a folder has three categories of how you can assign permissions: “Owners”, “Permissions”, and “Everyone Else”. Each of which can be assigned Read, Write, and Execute permissions. You have the option to recursively apply parent permissions to all child objects within the parent.
It’s important to have the security plan laid out at inception, otherwise, as stated above, applying permissions to items is a recursive activity. Access settings such as Read, Write, and Execute can all be granted and denied through the Azure Portal for easy administration as well as automated with other tools such as Powershell. Azure Data Lake is fully supported by Azure Active Directory for access administration
Role Based Access Control (RBAC) can be managed through Azure Active Directory (AAD). AAD Groups should be created based on department, function, and organizational structure. It is best practice to restrict access to data on a need-to-know basis.
How that plan is laid out depends on the specific security policy of the company. When designing a data lake security plan, the following attributes should be taken into consideration.
Data is secured both in motion and at rest in Azure Data Lake Store (ADLS). ADLS manages data encryption, decryption, and placement of the data automatically. ADLS also offers functionality to allow a data lake administrator to manage encryption.
Azure Data Lake uses a Master Encryption Key, which is stored in Azure Key Vault, to encrypt and decrypt data. Managing keys yourself provides some additional flexibility, but unless there is a strong reason to do so, leave the encryption to the Data Lake service to manage.
If you choose to manage your own keys, and accidentally delete or lose them, the data in ADLS cannot be decrypted unless you have a backup of the keys.
Regulations such as GDPR heavily affect data lakes by restricting the retention time and speculative use of the data. Organizations will not be allowed to keep filling the lake with more and more consumer data just for the purpose of searching for actionable patterns in the data.
Security for data lakes need to be handled the same way you would handle security for enterprise database systems.
Most data lakes are filled from the bottom up with data from operational applications such as ERP, IoT, and production systems. If the necessary actions and filters are taken at the source. (Ex. Data Masking) then the data itself is not the concern because it has little value in and of itself and often doesn’t have any meaning outside of a particular context.
The security threat that is left over is more about people abusing the data flowing into the lake, where it might be coming from, and any relationships that might exist within it.
Enterprises must work hard to develop the focus of their data management strategy to more effectively protect, preserve, and serve their digital assets. This involves investing in time and resources to fully create a lifecycle management strategy and to determine whether to use a flat structure or to leverage tiered protection.
The traditional premise of a Data Lifecycle Management was based on the fact that data was created, utilized, and then archived. Today, this premise might hold true for some transactional data, but many data sources now remain active from a read perspective, either on a sustained basis or during semi-predictable intervals.
Enterprises that know and understand the similarities and differences across their information, data and storage media, and are able to leverage this understanding to maximize usage of different storage tiers, can unlock value while removing complexity and costs.
Sources: Tim Negris, docs.microsoft.com, azure.microsoft.com, Philip Russom

Crafted by ![]()
Crafted by ![]()





