



As you might know, Python is now available as a preview feature in Power BI. It can be used to import, transform and visualize data. It has roughly the same workflow as R: you need to point to the Python interpreter on your local system, which will do all the magic for you.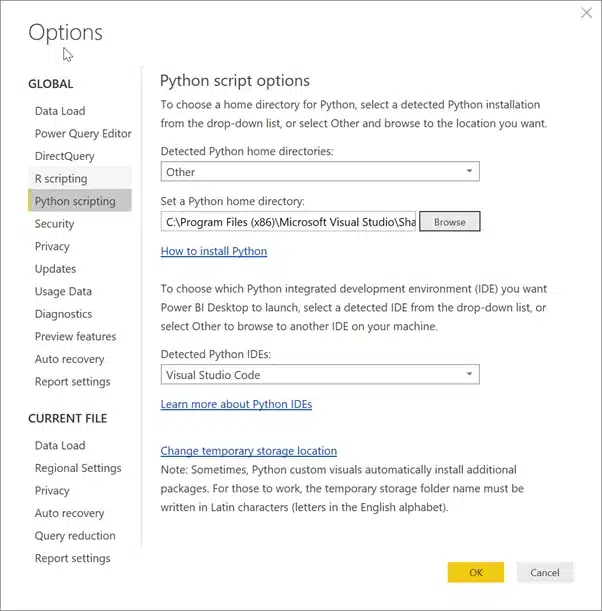
Because the Python functionality is still in preview, it cannot yet be used in the online service. I’m assuming this will change soon (just like it did with R). Nevertheless, let’s get to the issue and then to the solution that Python provided.
So, my boss Frederik Vandeputte, designed a very nice Power BI report that displays `De Tijdloze 100` (it’s a radio show that is broadcasted yearly on December 31 and is a playlist of the 100 most timeless songs – it’s based on input from the listeners, so it changes over the years). Read his updated blogpost on this topic. The data was mostly coming from a web-page dedicated to `De Tijdloze 100`: https://tijdloze.stijnshome.be/. But in the latest edition all data was not available, at least not for Power BI. Let’s have a look at the page/list for 2018:

Power BI can get the first 10 songs for each year, but not the complete list, as it’s not yet loaded into the DOM. Clicking on the text `Toon de hele lijst` will add the other 90 songs. But Power BI is not able to perform the click event before getting the data (it’s not a hyperlink). Therefore, we need another approach: Python to the rescue.
When looking at the html code, it became clear that all the data is available in the webpage, not just for one year, but for all years. Hooray! But it needed some serious tweaking. The data was completely translated into JavaScript objects, but this JavaScript framework added a translation step in between. Basically, it looked like this (this is just a small part of the JavaScript):
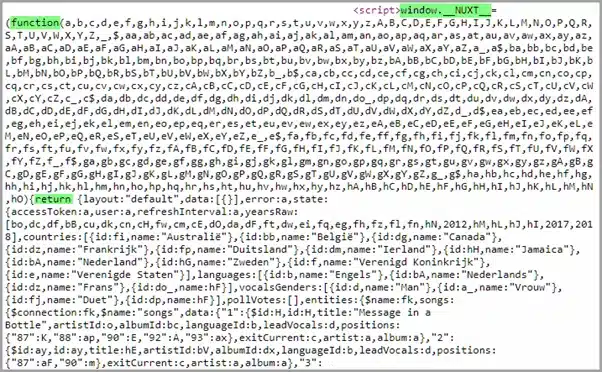
So, I was able to locate the data and mark some key-points, but not yet to extract it in a proper way (the above is still far from a suitable data model). Let’s just start with the beginning and extract the full HTML code. We can do it with this short piece of Python (the import statements are libraries that we’ll use in the script):

Not so difficult is it. Just don’t forget the utf-8 decoding, as you want special characters to display properly. So far, so good. In a second step it’s somewhat more difficult, because we’re using regular expressions to extract the <script> tag we’re looking for:
![]()
Use the `r` in front of the string, otherwise your regular expression will become even harder to read (you would have to backslash special characters).
As mentioned, there is a translation in the JavaScript framework. This means that instead of using the real values of the songs/artists/… they have been replaced by other (at random?) values. Strangely enough not all values have been replaced. But we’ll handle that matter with Power BI conditional columns. First let’s get two important arrays: one that holds the translations (they are the parameters of the JavaScript function) and one that holds the real values (these are the values passed to this function). One appears in the beginning of the JavaScript, the other one at the end.

Both lists should be equal in length, otherwise it would not be much of a key-value thing. And don’t sort the lists yet, as we need them in the order they arrived. So now we have our mapping `table` with proper values. When using Spyder (that comes with Anaconda) you can easily see the content of the lists in the variable explorer:

After some extra clean-up wit regular expressions (removing things like unwanted quotes and backslashes) we seem to be good. We’ll stitch both lists together further on.
Next is the data itself. This is presented in JSON, but the JavaScript variant, not proper JSON: JSON needs double quotes for every key. The JavaScript function JSON.stringify takes care of this translation in JavaScript, but for Python I was not able to find exactly the same functionality (json.dumps does not do the trick in this case). I’m still learning Python, so feel free to comment on this post if you found a better way to do this. Anyhow, I took care of it with – again – regular expressions and some find/replace actions (you can find the full Python code within the Power BI file that is available for download beneath this blogpost):
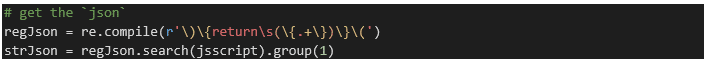

This was for the songs. After doing the same for the artists we have a valid JSON string. As simple as that 😊. Don’t be intimidated by regular expressions: check out this tutuorial.
In the end, we just need to return the dataset as Pandas data frames (that’s what Power BI expects). Hence, we use functions that come with Pandas to convert the JSON and lists to the proper data frames.

Once we run the code in Power BI (with `Python script` as our source), we should see our three queries’: Songs, Artists and KeyValue.
The KeyValue query is only used to get meaningful data in the other queries (these can be rankings, titles, years…):
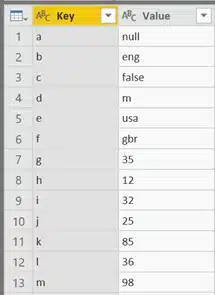
This KeyValue query will not be loaded in the data-model, it’s only used to lookup information (in Power BI called a merge).
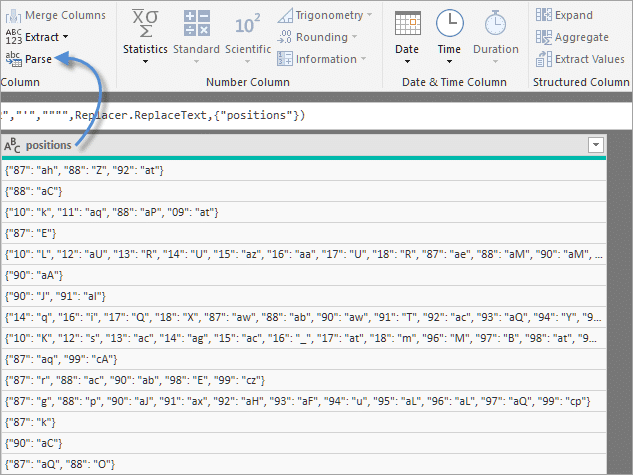
Each song contains the position for every year it made it to the top 100. The positions are wrapped in their own JSON object, so we can easily parse it with built-in Power BI functionality:
At the end, we’re able to present a neat model that does not resemble any of the Python, JavaScript, RegEx, M adventure we encountered.
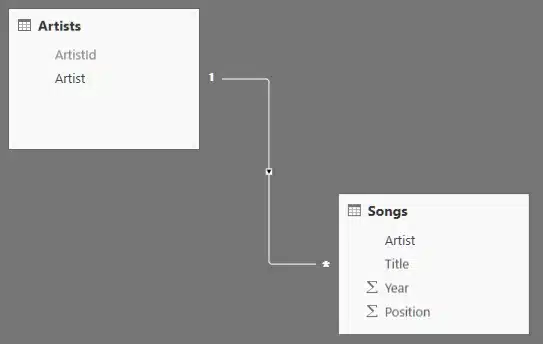
But most of all, it reflects the Power in Power BI, which is now even more than before a versatile and convincing BI tool with this newly added Python integration.

Crafted by ![]()
Crafted by ![]()





