



There is a large variety of data sources from which we can extract, and that number is not likely going to decrease. The ETL path that has to be taken for each source can vary heavily depending on all kinds of factors including application architecture, company security, departmental policies, etcetera. Middle-sized to large companies tend to use multiple applications from which data can be extracted to feed the greedy monster that is BI. In our case it is safe to say that ‘greed is good’ with the words of Gordon Gekko.
So, to move on with a more specific case in which we could encounter a blockage to extract data directly from the database:
Developer team A from web shop B is responsible for further developing and maintaining their main web-based business application towards the customers. Other company departments, including BI, want to incorporate the data in some way for each of their own purposes. The following scheme illustrates the situation as-is:
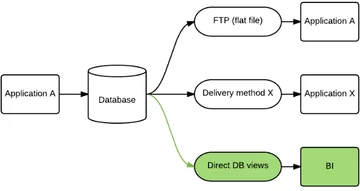
The existing data delivery to BI was done through database views since the database architecture is obscure to say the least and doesn’t make sense to other developers than developer team A. The views contain technical and business logic that is vital in providing correct data. Since there is a constant stream of incoming business requests that need to be implemented into the application, there could very well be adjustments necessary in the coding towards the different child applications including BI. Without it, the incoming data in our data warehouse could contain faulty data…
After reviewing this situation developer team ‘A’, concluded that all the different data presenting layers should be replaced by one complete API layer that can be used by all. API stands for application program interface. This concept defines how applications should be able to interact with each other without having to know the technical details of each other. In our specific case it’s a building block from which every child application can call a method to provide each of them with the correct data.
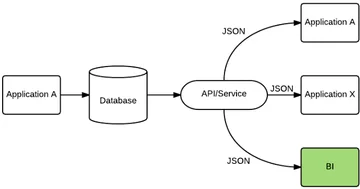
This would offer the following main benefits:
Now, remember that this is a simple example, to make a switch like this, there are a lot of other factors to take into account like data volume, connection speed, et cetera. This solution is technically not feasible in every situation and should be thoroughly analyzed and discussed.
Okay, to start of the development at our side, we are going to discuss two ways to consume the extracted JSON stream into SSIS.
The public JSON feed that we will be using will be a public weather service. The JSON response can be triggered by going to the web URL and providing two parameters city name and country code:

Since this isn’t reader-friendly let’s convert that string to a more readable format. There are a lot of online conversion applications. For this example, I’ve used <a href=”http://www.json-xls.com/json2xls”>this file</a> to convert my JSON to Excel.
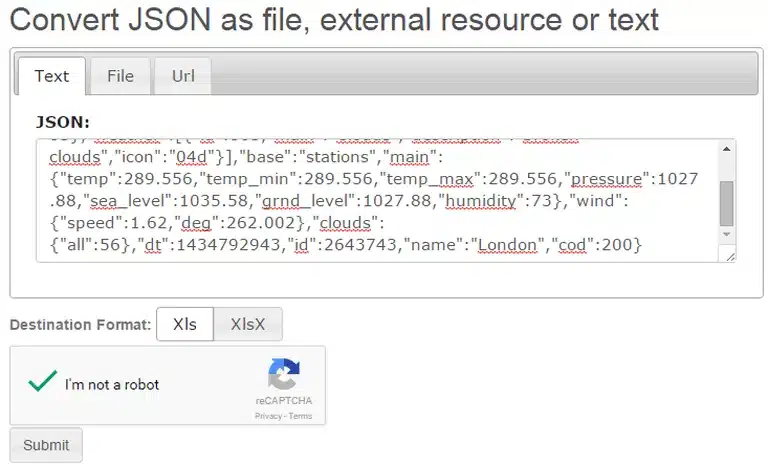
We see that there are multiple objects, but we are going to focus on the weather object.
The first method we are going to try is through a script component. Remember we are going to pass 2 parameters to the <a href=”http://api.openweathermap.org/data/2.5/weather?q=AddCityName,AddCountryCode”>service URL</a>
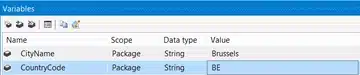
To make this dynamic, two variables have been added to the package:
Then we added a data flow task and in the data flow we can add a script component and select it as a ‘Source’.
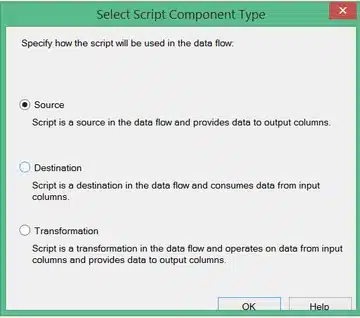
After that we select our variables so that we can use the values in our code.
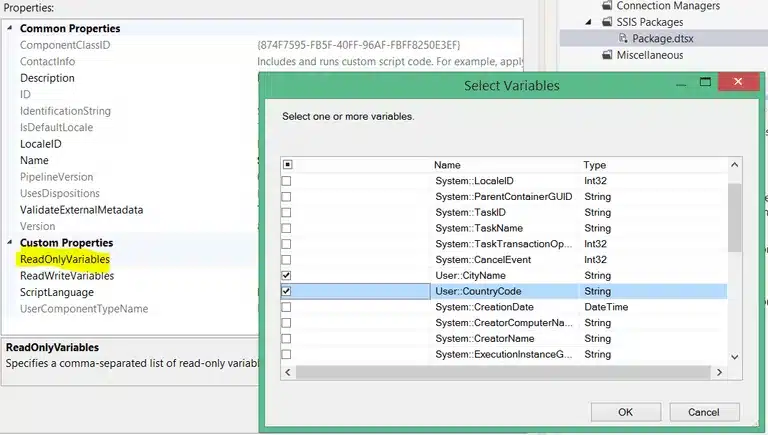
This component will be outputting data, so we will have to add outputs for our four weather attributes:
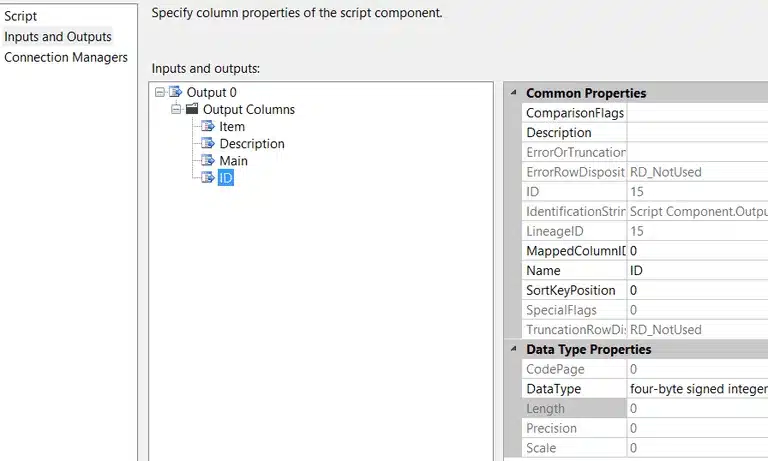
Now, we are ready to open the script editor. First, we must add the Web.Extensions reference.
You will find the programming code inside the project. It consists of the following blocks:
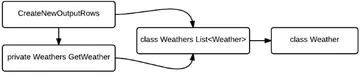
Class weather will contain our 4 attributes. We will create a list of this class to convert our deserialized JSON into. The key function to convert the JSON string to a list of the weather object:
![]()
Private Weather method will call the webservice and convert the response to an array of Weather objects. This array will be returned to the calling block CreateNewOutputRows. This block will convert the array to rows which we need to output.
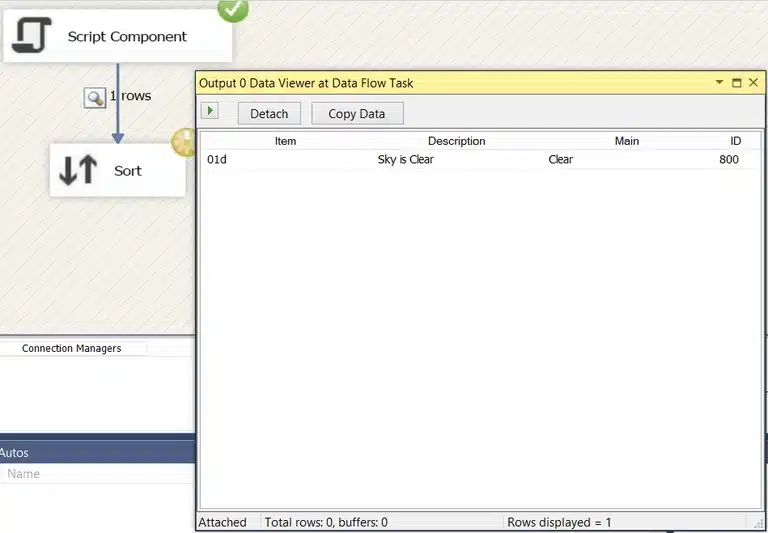
When we execute the package, we see that the output contains a row for the weather in Brussels:
There are two ways to install the JSON component:
After the installation, I had the issue of not seeing the JSON component in my SSIS toolbox. On the discussions page on codeplex there were people experiencing the same issue. They experimented with uninstalling/re-adding the dll in the PipelineComponents folder that you can find in your SQL server installation folder. I copied the necessary gacutil components to the PipelineComponents folder. These components can be found in the Microsoft SDK’s folder:
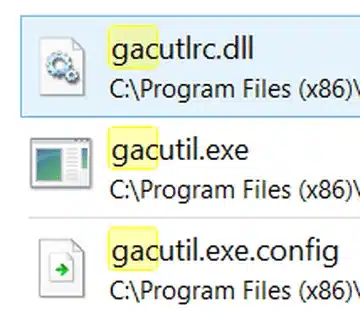
Then for uninstalling I issued the following commands:
For re-installing them I issued the following commands:
You should then receive a message that the dll is successfully added to the cache. After this I restarted data tools, and the new component was visible in the data flow. To start things up I’ve added an extra variable to make the URL dynamic like in the script task, this variable will be used as the source of our JSON component:
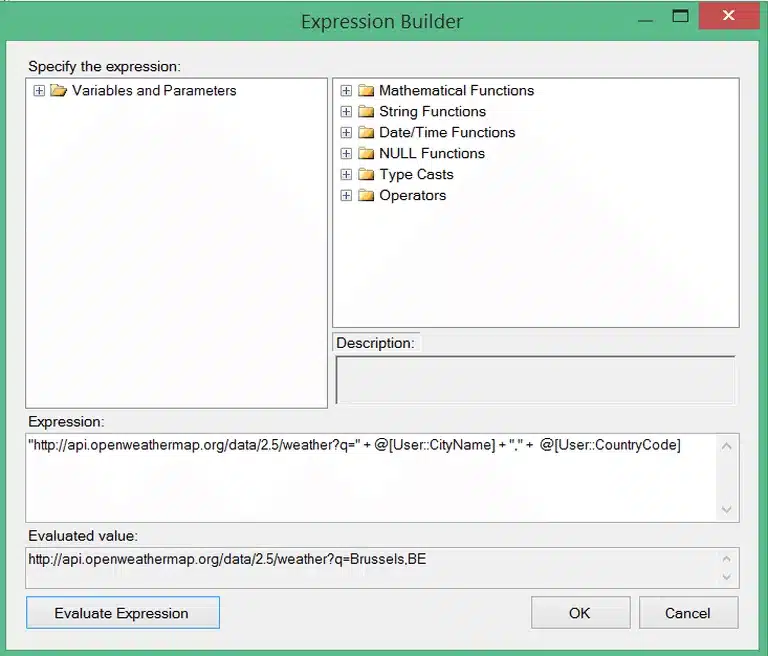
Since the JSON source component has different options including a dynamic one for the source type (Web URL or file location), I preferred to set up the component using the ‘WebUrlVariable’ option.
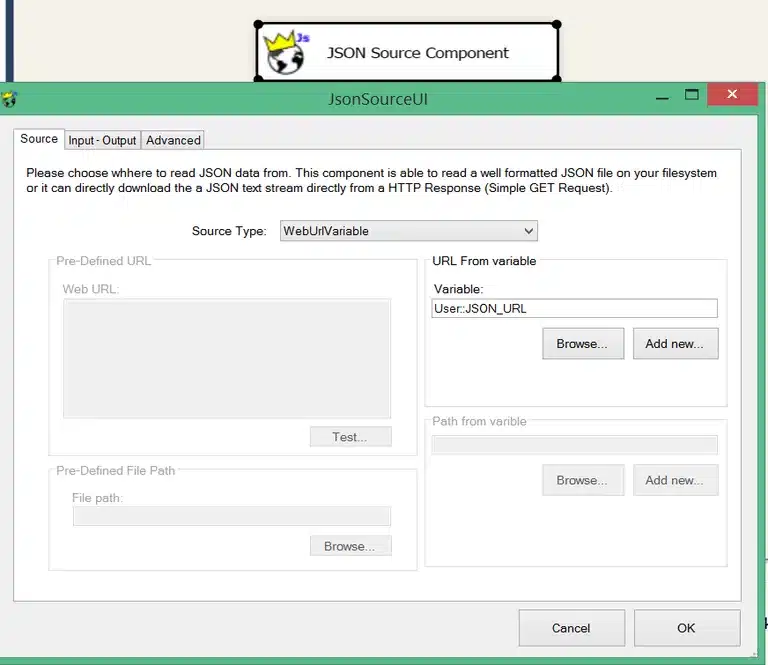
So, after the source tab has been set up to work with the variable, we can move on to the ‘Input-Output’ tab where we will define our attributes that we will retrieve from the JSON response. I must note here that my ID attribute, which represents an integer, could not be mapped to an SSIS integer data type because it always threw the following error:
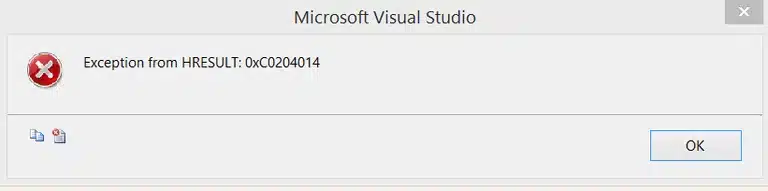
Perhaps I did something wrong, but since this is a quick walkthrough and conversion could happen afterwards in the flow, I mapped it to a string data type:
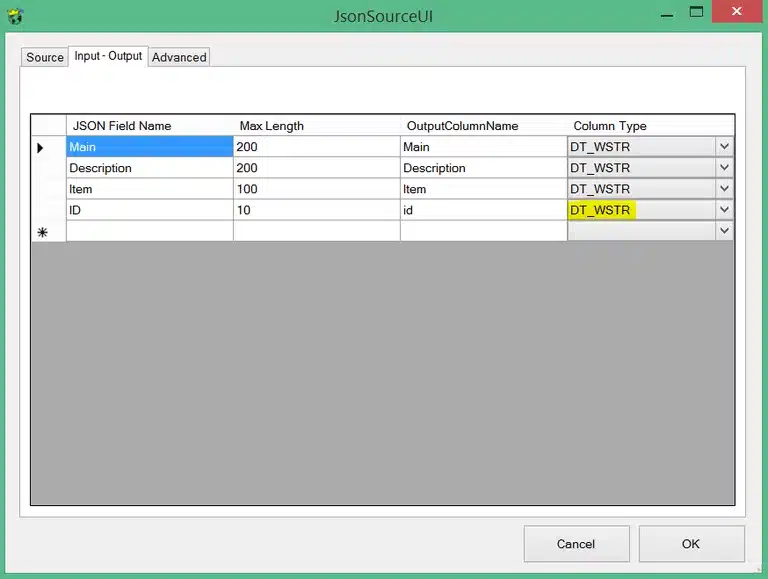
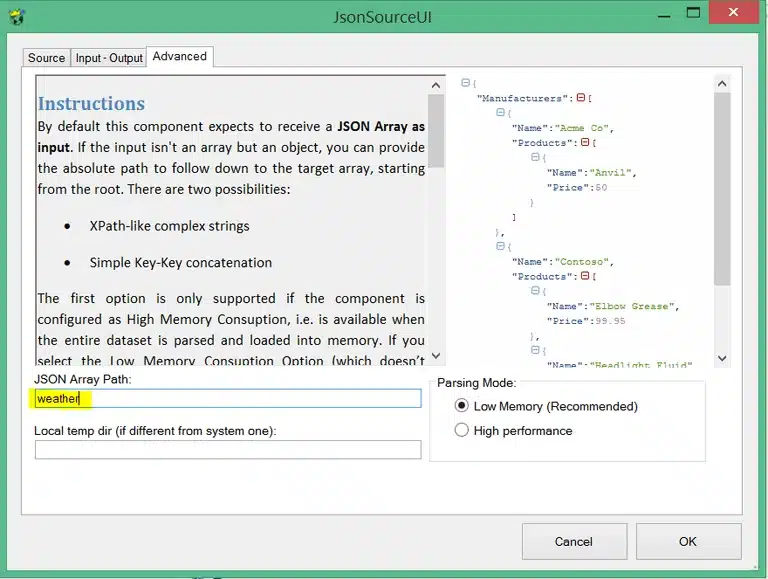
Finally in the advanced tab we can set some extra settings regarding how we want to “walk” the JSON response which has impact on which parsing mode to use. That parsing mode has consequences towards the performance. You can look at the instructions in the component and play around with it to notice what can be done and what can’t:
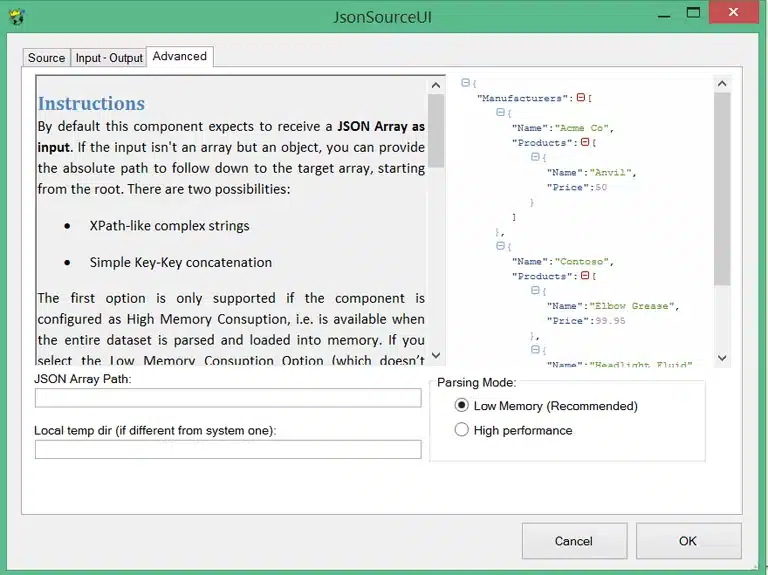
For our example we use a simple key-key concatenation to access the weather object:
Finally, we execute the data flow and get the following result.
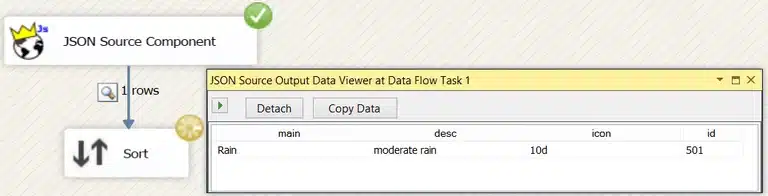
The setup for these tests was simple. Not a lot of coding was necessary for getting a basic working data flow. However, when a JSON response gets more complex, so will your initial setup. The choice of option depends on what knowledge the developer has regarding XPath or .NET coding. These two options I’ve shown here aren’t the only options, so alternatives are possible.
Regarding the replacement of the more traditional ETL setup involving a direct database connection as the source, I don’t think one should jump blindly into this new adventure. As always it depends on the benefits and disadvantages that will be put into the scale, but with big data volumes though I think JSON could be a potential bottleneck.

Crafted by ![]()
Crafted by ![]()





