



Imagine your client gives you an Excel file as the SSIS source for a new project. When you load the data, a few things stand out. The data type is not aligned as expected and some of the rows are not filled with the data provided.
You try to change the input data type in the Excel source component. However, you can’t seem to get the output you want. So, what’s the problem?
Well, let’s look at the input.
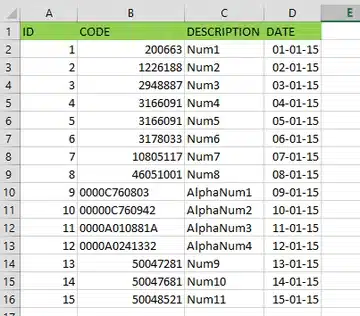
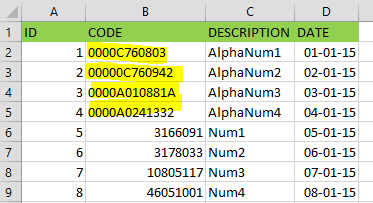
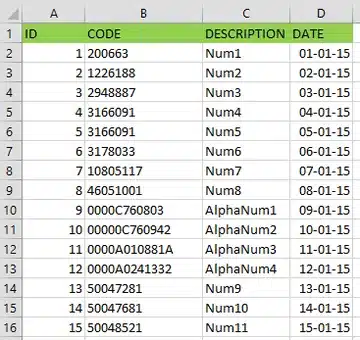
The first thing we notice is that the CODE column consists of two kinds of data types: numeric and alphanumeric (rows 9 to 12).
When we load this into our database, rows 9 to 12 are not loaded correctly and are shown as null values.
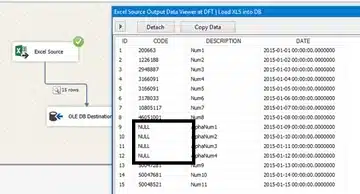
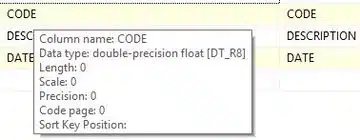
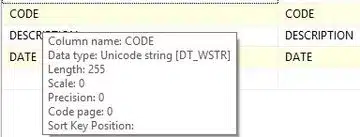
The Excel source suggests that the data type of the CODE column is numeric (float), as shown below.
This happens even when we set the fixed outcome of the source to be alphanumeric:
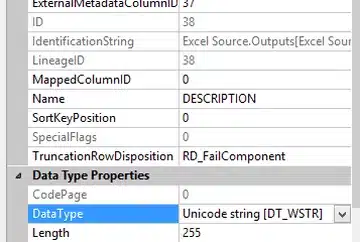
The first question is, why is the value given as a float when the input clearly shows that the input data are a combination of alphanumeric and numeric values?
Some research on MSDN reveals the following information:
IMEX is set to 1, but if we investigate further, we find following:
“NOTE: Setting IMEX=1 tells the driver to use Import mode. In this state, the registry setting ImportMixedTypes=Text will be noticed. This forces mixed data to be converted to text. For this to work reliably, you may also have to modify the registry setting, TypeGuessRows=8. The ISAM driver by default looks at the first eight rows and from that sampling determines the datatype. If this eight-row sampling is all numeric, then setting IMEX=1 will not convert the default datatype to Text; it will remain numeric. ”
As a side note, you aren’t allowed to change the registry settings…
But if you want to change them, here is where to find them:
For 32-bit
HKEY_LOCAL_MACHINE\Software\Microsoft\Jet\4.0\Engines\Excel
For 64-bit
HKEY_LOCAL_MACHINE\SOFTWARE\Wow6432Node\Microsoft\Jet\4.0\Engines\Excel
Also, for 64-bit
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Office\14.0\Access Connectivity Engine\Engines\Excel
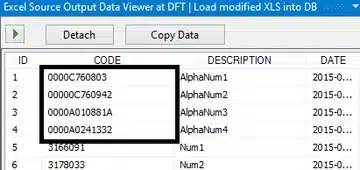
We had the bad luck of the first eight rows being of numeric type, with the first alphanumeric value in the 9th row. When we take a new Excel file that has alphanumeric values for the top rows, you’ll notice that the data type is now alphanumeric.
And loading this into the database gives the following result:
A simple solution, which has proven to be successful so far.
Note that we don’t format the cells as “General” but as “Text”.
This is how to do it:
1. Select the columns that are causing the issue and select “Format Cells…”.
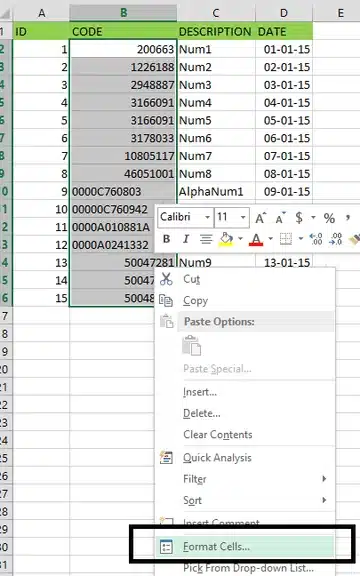
2. In this dialog box, go to the “Number” tab.
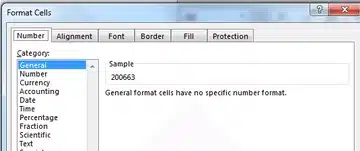
As you can see, the cell formatting is set to “General”, meaning Excel decides what type of formatting is applied to each individual cell. We set this value to “Text” instead of “General”.
3. Cells are now formatted as having textual values.
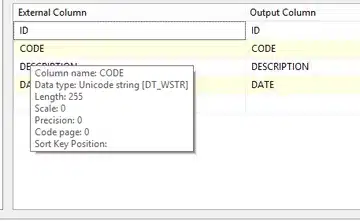
When we go back into the SSIS Excel source, we find a welcome change in the input data types.
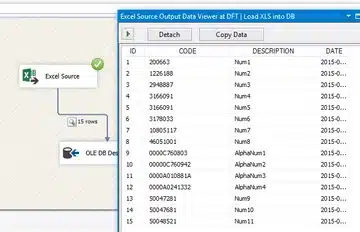
And this is the result on execution – no more null values for records 9 to 12:
One of the easiest ways of avoiding this issue is to work with CSV files instead. A CSV file stores tabular data as plain text data and allows you to choose the best possible data type for the project (or what you expect it to be). This gives you more control of the data and the data flow.
If plain data is dropped into SQL from Excel, another option is to use OpenRowSet. This allows reading the XLS file from within SQL and insert it directly from the same query.

Crafted by ![]()
Crafted by ![]()





