



Kohera’s Modern Data platform does not come with a canned data model by default. This makes the framework extremely flexible to adapt to a variety of project workflows, but it also means during the Analysis phase we will need to think about how to structure the data before continuing.
In the simplest case, you will have an IOT object that populates a single Data lake object. More advanced cases will have multiple inter-related objects, some filled in at the same time and others filled out separately.
Our framework makes it easy to start simple and add more complexity when needed.
This document exists to describe the process leading to the key decision whether to use a traditional relational model, or to use an Entity-Attribute-Value (EAV) model (also commonly referred to as an open schema).
The key difference in the two approaches is the level of flexibility your model has in adapting to changing project requirements, especially when new attribute definitions are needed. At a high level, attributes are added as columns to a relational schema, but as rows in an EAV schema. This means that an EAV schema can easily be administered, while a relational schema typically needs to be modified by a specialist for example a database administrator.
We support both approaches, though classic frameworks have traditionally better support for relational schema approach, one particular strength of an EAV approach is the ability to create “Report” or “campaign” driven datasets. Essentially, you can design workflows that allow project participants to define their own data collection requirements.
In a Databricks environment EAV-style schemas are supported via the use of relational objects that define a meta-schema. In addition, these approaches are often mixed within the same project. So, using an EAV model doesn’t mean forgoing a relational schema.
In this document, we’ll discuss the key features of the relational and EAV models and conclude with a checklist leading to our decision of which model to use.
In a relational model, there is a well-defined correspondence between the elements in your source system and the columns on the reporting database table you want to populate. This is much more straightforward than an EAV approach and makes the code and templates easier to read. Each table can be defined as a distinct workflow and exist within specific constraints and requirements that are enforced both inside the data lake as at the database level.
In our framework, the relational approach requires defining one or more dimension and Fact objects which can then be used to generate ELT scripts that create the actual reporting database tables. Once these models are created, we can then create a framework using Azure Data Factory in combination with Databricks to list, retrieve, create, and update the records in the reporting database.
Whenever you add or change a model field, you might have to create a new script to make the appropriate modifications to the database. If you want to change the business logic contained inside the Fact and the Dimensions you will also need to update your global templates to reflect the new field definitions. These steps are not automatic and might need non-trivial knowledge of both the dataflow and the Framework.
In an EAV model, the source data’s fields represent a one-to-many relationship between a primary Entity table and a Value table. Each row in the Value table corresponds to a “field”, which is defined as a row in a third Attribute table. In effect, the Value table creates a many-to-many link between the Entity table and the Attribute table.
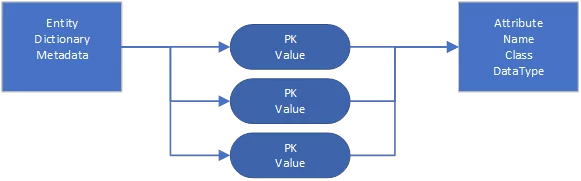
In our framework, the EAV approach typically means defining your model classes as subclasses of the base Entity type you want to use. For example, to define a model that uses the EAV-style Object structure, you would create it as a subclass of ObjectModel.
Any relational fields can then be defined on your model as usual. Our general rule of thumb is that if a field is critical to the interpretation of a record, is a foreign key, or is going to referenced by name anywhere in the code, it should be defined as a traditional relational field. For Example if you defined code tables for translations it is not efficient to store these tables in an EAV object, if you keep them relational they’ll be easier to use.
All other fields can be defined as rows in the Attribute table, and new attributes can be added if needed. The key drawback of an EAV approach is no longer performance – inside our framework the EAV model has some definite performance advantages but you have to take into consideration that an EAV model definitely increases the level of abstraction and can obfuscate the application code.
With an EAV model, you will instead need to create branching logic that can adapt to each field type on the fly. There will not be a single reference to a specific Attribute name anywhere in the code – which makes reasoning about changes difficult.
That said, if you are comfortable with this abstraction, it becomes a very powerful tool for building adaptable data-applications that don’t need extensive developer intervention when project definitions or business requirements change.
We will recommend the use a relational model if:
We recommend the use of an EAV model if:
Due to the nature of this project, and the uncertainties on the business side and especially because of the physical deletes in the source we opt for the ERAV model.
The Entity-Record-Attribute-Value (ERAV) data model is an extension to Entity-Attribute-Value (EAV) that adds support for maintaining multiple versions of a model with different provenance. As the name implies, ERAV is made up of four distinct components:
For many operational uses, the attribute values for each entities’ records can be “merged” into a single set, providing the appearance of a regular EAV. However, the actual data is kept distinct, providing enhanced flexibility for tracking provenance of data collected from multiple versions of the source systems.
When your dataset contains various versions in time, and the list of attributes for each event in the series might change over time, the EAV model will be useful to provide the flexibility to adapt to changing attribute definitions.
However, if the actual data needs to be tracked to individual unique entities in time the ERAV model will provide the possibility to track changes to these individual entities (events). The ERAV model solves the versioning challenge by making it possible to import data for the same entity more than once. But also, to check if an entity already exists inside a specific time interval. Each subsequent import is treated as a separate record but linked back to the entity so that the data can be merged for operational use. ERAV, enables this by separating the event from its provenance record. The event entity retains metadata about the original value (e.g., change date), while the meta data about provenance (e.g., id, date/time entered, review status) is moved to a separate report entity. This approach enables maintaining multifaceted data for the same event.
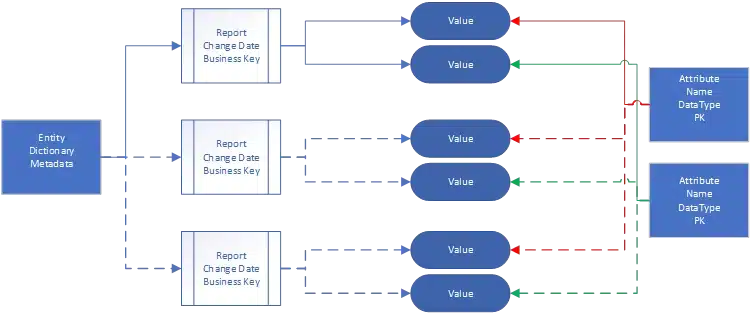
A critical component to ERAV is the concept of a Business key for the Entity/Event model. A Business key in this context is a set of fields that both occur naturally in the data, and uniquely identify a record from a business point of view. An important feature of a business key is that it does not need to be assigned a priori by a central mechanism. (By contrast, a typical primary key is assigned centrally, at the time the record is registered with the database.) Without a usable business key, there is no easy way to determine which entity is being described in subsequent reports. For many projects, a Business key, combined with a date will always allow for the correct interpretation and will describe the same event.
ERAV is particularly useful for combining values from multiple records with different attributes. The “merging” feature of ERAV makes it possible to present a single unified description of an Entity/Event, useful for analysis and most typical use cases. Unlike other versioning models and generic EAV, this can be done without obfuscating the metadata associated with each individual report (source object, , etc.). When a more robust inquiry is needed about the provenance of a particular data point, the reports can also be used to determine this information.
However, it is possible that two records will contain an overlapping attribute set. In this case, the values may conflict. In traditional versioning models, any conflicts would need to be resolved immediately, as there can usually be only one active version of an entity. This is not always practical, especially when dealing with bulk uploads of data. ERAV smooths over these conflicts, allowing them to be resolved later. Until the conflicts are resolved, the value from the most authoritative report is selected for each attribute when merging data for analysis. “Authoritative” could often just be the most recent value.
The reference implementation of an ERAV is particularly suited for data series that change over time and are using data coming from multiple sources.
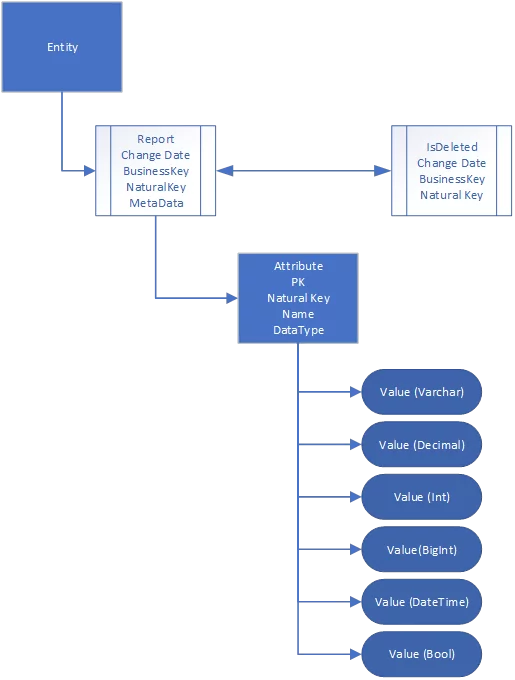
The Reports tables can be supplemented/exchanged with multiple metadata tables that describe an attribute in further detail. This metadata information can then be used to automate generation of dataflows. A separate meta table will be included to mark deleted records.
As a variation on this approach and to retain the datatypes from the source system, we implement a strongly typed approach where a value of given data type is recorded in a table specific to that data type. An example schema is shown below and includes the metadata storage inside the Report Objects.

Crafted by ![]()
Crafted by ![]()





