



(Spoiler alert, you can’t :) )
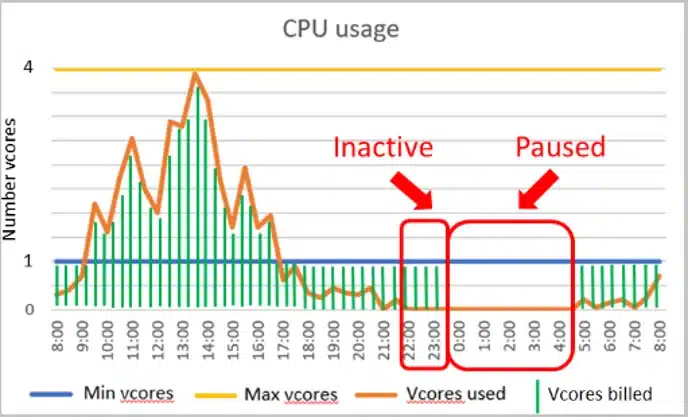
But first things first, what the heck is serverless? Azure SQL Database serverless is a new compute tier made for single databases. This new model automatically scales the compute based on the actual workload per second. This means that you only have to pay for the compute resources (memory & vCores) you use. Furthermore, serverless has an autopause function. It will pause your database when it remains inactive for a period of minimum 1 hour. For a paused database, only the storage is charged.
Only paying what you use, it does seem tempting doesn’t it? Still, there are reasons why provisioned tiers might be a better fit for your workload. First of all, as per writing only general purpose is supported in the serverless compute tier. If you are using business critical and your workload needs the improved I/O performance then serverless probably won’t be a good fit for you. Secondly, you only receive 3GB of memory per vCore whereas you receive 5,5 or 7GB per vCore in the provisioned tiers, depending on the generation of CPU you choose. Besides, you can maximally assign 16 vCores to serverless.
It’s also possible that you experience some delay in the ramp-up of the compute power after idle periods. In extreme circumstances, it’s even possible that the underlying host cannot provision enough resources within a few minutes. In that case “load balancing” will automatically occur. During load balancing the database remains online except for a brief period at the end of the process when all connections are dropped. This behavior is comparable with resizing a database in any provisioned tier.
Lastly, after an auto-pause the first connection to the database will fail.
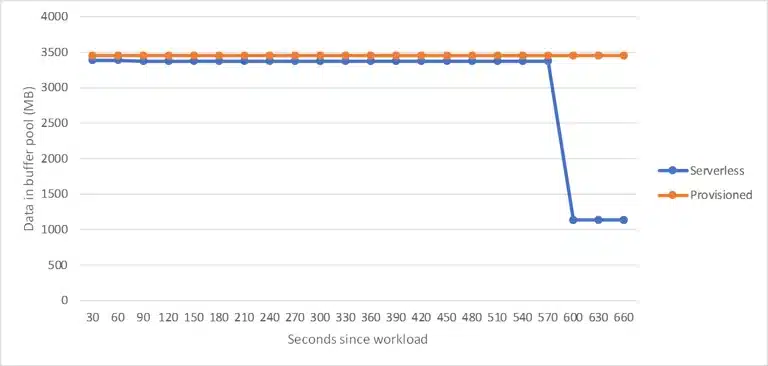
Although the beforementioned points are all valid, it isn’t what would stop me from using serverless. The first possible obstruction lies in the way that SQL Server manages its memory. As we’ve all learned when installing an on premise SQL Server instance, you should specify the memory boundaries and let the SQL OS manage its own memory. Traditionally SQL Server isn’t very keen on releasing memory to the OS. When using serverless databases on the other hand, memory is reclaimed from the database more frequently. This process is triggered whenever cache and CPU utilization is low. Memory entries to free up are chosen the same way as for provisioned databases when memory pressure is high.
This can result in increased disk I/O and query plan compilations after a period of low usage. The total cache size will never go below its minimum size. This boundary is defined by the configured vCore range. It’s important to realize that despite the impact on performance, this behavior certainly has its merits. The sooner memory is released, the less there will be charged.
To test this mechanism I started an identical workload on a serverless and on a provisioned database. The serverless database was configured to use between 0,5 and 1 vCore. Afterwards I monitored the size of the buffer pool. As you can see, after approximately 10 minutes the serverless’ buffer pool was reduced to 1GB. The buffer pool of the provisioned database remained stable, no datapages were flushed from cache.
https://docs.microsoft.com/en-gb/azure 1
The main goal of using serverless instead of provisioned database is to reduce cost. It’s very important to gain knowledge about your workload before switching to serverless. The storage cost is the same as for provisioned databases. The compute cost on the other hand is calculated based on the vCores and memory used:
At first sight it would seem that, unless your database is constantly using all available resources, serverless would always be the cheapest option. There is a catch though… Serverless compute resources are twice the price of provisioned compute resources. In other words, a constant high load would cost more in serverless than it would in provisioned. The use cases you are looking for are single databases with an intermittent and unpredictable load followed by periods of lower utilization or inactivity. Typical examples are databases used for dev environments.
Although the serverless compute tier isn’t a fit for each database, it certainly has its use cases. I’ve used it a couple of times and it can save you a serious amount of money. Just keep in mind that there might be a negative impact on performance and that you must first examine your workload before choosing for serverless.

Crafted by ![]()
Crafted by ![]()





